kity54
Usuario

BUENO PRIMERO YASE QUE AHI UN pOST PERO ES PARA BAJAR LOS BLOOPERS ESDTE ES PARA VERLOS SI ES REPOST ME MANDAN EL LINK QUE LO BORRO PRIMERO UNA PRESENTACION DE FRIENDS QUE TA BUENA: link: http://www.videos-star.com/watch.php?video=gQjoHzMRsM8 Bloopers Temporada 1: link: Temporada 2: link: http://www.videos-star.com/watch.php?video=y_tYU41Wn_E Temporada 3: link: http://www.videos-star.com/watch.php?video=i3BxifEYmR4 Temporada 4: link: http://www.videos-star.com/watch.php?video=8ezA9EegDGg Temporada 5 NO LO ENCONTRE Temporada 6: link: http://www.videos-star.com/watch.php?video=8xAPryDSDLA Temporada 7: link: http://www.videos-star.com/watch.php?video=N-qBXLvl0qU Temporada 8: link: http://www.videos-star.com/watch.php?video=UyRq1GCWMXE Temporada 9: link: http://www.videos-star.com/watch.php?video=OpQY-Gczji4 Temporada 10 Parte 1: link: http://www.videos-star.com/watch.php?video=GBmUO31sJ1M Temporada 10 Parte 2: link: http://www.videos-star.com/watch.php?video=nDb3bmgmnHg UNA DE LAS MEJORES SERIES
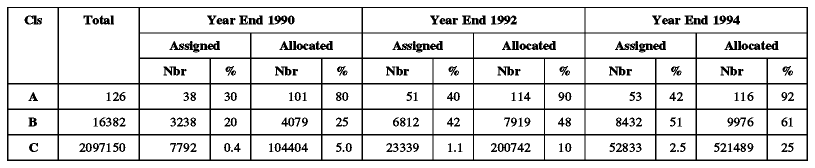
Registrate y eliminá la publicidad! 2.2.5 El problema del agotamiento las direcciones IP El número de redes en Internet se ha ido doblando aproximadamente cada año durante varios años. Sin embargo, el uso de las redes de clase A, B y C difiere mucho: la mayoría de las redes asignadas a finales de 1980 eran de clase B, y en 1990 se hizo evidente que, de continuar si la tendencia, el último número de red de clase B sería asignado en 1994. Por otro lado, las redes de clase C apenas se usaban. La razón de esta tendencia era que la mayoría de los usuarios potenciales hallaban a las redes de clase B lo bastante grandes para sus necesidades previstas, ya que acomoda hasta 65534 hosts, mientras que un red de clase C, con un máximo de 254 hosts, restringe considerablemente el crecimiento potencial de hasta las redes pequeñas. Es más, la mayoría de las redes de clase B estaban asignadas a redes pequeñas. Hay un número relativamente pequeño de redes que necesiten 65,534 direcciones de hosts, pero muy pocas para las 254 sea un límite adecuado. En resumen, aunque las divisiones de clase A, B y C de las direcciones IP son lógicas y fáciles de usar(puesto que se producen a nivel de byte), en perspectiva no son las más prácticas, ya que las redes de clase C son demasiado pequeñas para la mayoría de las organizaciones mientras son demasiado grandes para ser bien aprovechadas por nadie excepto por las organizaciones más grandes. Tabla - uso de las direcciones de red IP entre 1990 y 1994 muestra el uso de las direcciones de red IP entre 1990 y 1994. Tabla: uso de las direcciones de red IP entre 1990 y 1994. - Fuente: netinfo/ip_network_allocations.95Jan del FTP rs.internic.net Algunos aspectos de esta tabla requieren explicación. Assigned(asignado) La cantidad de números de red en uso. Las cantidades de la clase C son algo imprecisas, puesto que no incluyen muchas redes de clase C en Europa que se destinaron a RIPE, y fueron asignadas posteriormente, aunque aún están registradas como parte de RIPE. Allocated(reservado) Incluye todas las redes asignadas y adicionalmente, aquellas redes que han sido reservadas bien por IANA(por ejemplo, todas las 63 redes de clase A) o que IANA ha sido destinado a registros nacionales que posteriormente podrán asignarlas. Por ejemplo, IANA reservó 64,783 redes de clase C en agosto de 1992, y 65,959 en julio de 1993. Nota: Según IANA, el estado de un red es asignado o reservado, pero esta tabla trata el estado reservado como un superconjunto del asignado; el porcentaje real se puede calcular restando de 100 el porcentaje reservado para determinar cuánto espacio "libre" queda. Otra forma de ver estos datos es examinar la proporción del espacio de direcciones que ha sido usado: las cantidades de la tabla no muestran, por ejemplo, que el espacio de direcciones de clase A es tan grande como el de las clases B y C combinados, o que teóricamente una sola red de clase A puede tener tantos host como 66,000 redes de clase C. Figura - Uso del espacio de direcciones IP muestra el uso del espacio de direcciones desde este punto de vista. El gráfico representa un espacio de direcciones de 32 bits, es decir, 4,294,967,296 direcciones. Las direcciones de clase A, B y C se dividen del modo siguiente: Assigned(asignado) La porción del espacio de direcciones localizadas en redes asignadas. La cantidad real es en realidad mucho menor, puesto que es probable que cada red tenga bastante espacio libre, pero como este espacio no se puede utilizar fuera de la organización que controla la red, debe considerarse como espacio efectivo. Se muestra en porciones resaltadas: el área resultante de unir todas las porciones representa la proporción del espacio de direcciones IP en uso. Allocated(reservado) La porción del espacio de direcciones que se halla en redes que reservadas pero no asignadas más la porción de espacio perdida en números como el 0 de las redes de clase A y el 127(loopback). El espacio reservado se muestra con porciones sombreadas. Unallocated(no reservado) El resto del espacio de las clases A, B, C está libre; se muestra con una porción sin sombrear. Las porciones de las clases A, B, C se muestran con bordes progresivamente más finos. La clase A comienza a las 3 en punto y se mueve en sentido anti-horario hacia las clases B y C. Class D(clase D) Una decimosexta parte del espacio total es absorbido por las direcciones de multicast de clase D. Se consideran direcciones en uso por lo que la porción correspondiente aparece resaltada. Class E(clase E) La decimosexta parte restante del espacio de direcciones: IANA ha reservado esa parte, correspondiente a las direcciones IP con los cuatro bits de orden superior puestos a uno. Figura: Uso del espacio de direcciones Si se examina Tabla - Uso de las direcciones IP entre 1990 y 1994 se verá que es de 1990, el número de redes asignadas de clase B se ha ido incrementado a una tasa mucho más baja que el número total de redes asignadas y que el agotamiento previsto de los números de clase B. La razón es que la política del InterNIC sobre la concesión de números de red cambió en desde 1990 para preservar el espacio de direcciones existente, en particular para frenar el agotamiento del espacio de direcciones de clase B. Las nuevas políticas se pueden resumir en: * La mitad superior del espacio de direcciones de clase A se reserva indefinidamente para tener la posibilidad de usarlo en la transición a un nuevo sistema de numeración. * Las redes de clase B sólo se asignan a organizaciones que puedan probar claramente que las necesitan. Lo mismo ocurre, por supuesto, con las direcciones de clase A. Los requerimientos para las redes de clase B son que la organización solicitante o Tenga un esquema de subnetting con más de 32 subredes dentro de su red operativa y o Tenga más de 4096 hosts Cualquier solicitud de una red de clase A se trataría considerando estrictamente el caso particular. * A las organizaciones que no satisfacen los requerimientos para una red de clase B se les asigna un bloque de redes e clase C numeradas consecutivamente. * La mitad inferior del espacio de direcciones de clase C(números de red del 192.0.0 al 223.255.245) se divide en 8 bloques que se para las autoridades regionales están reservadas del siguiente modo: 192.0.0 - 193.255.255 Multi-regional 194.0.0 - 195.255.255 Europa 196.0.0 - 197.255.255 Otros 198.0.0 - 199.255.255 Norte América 200.0.0 - 201.255.255 Centro y Sur América 202.0.0 - 203.255.255 Borde del Pacífico 204.0.0 - 205.255.255 Otros 206.0.0 - 207.255.255 Otros Los rangos definidos como "otros" se utilizan donde hace falta flexibilidad por encima de las limitaciones de las fronteras regionales. El rango definido como "multi-regional" incluye las redes de clase C que habían sido asignadas antes de que se adoptase este nuevo esquema. El InterNIC asignó 192 redes, y 193 habían sido previamente reservadas para el RIPE en Europa. La mitad superior del espacio de direcciones de clase C(208.0.0 a 223.255.255) permanece sin asignar y sin reservar. * En las organizaciones que tienen una serie de números de clase C, el rango asignado contiene números de red contiguos a nivel de bit y el número de redes de ese rango es una potencia de dos. Es decir, todas las direcciones IP en ese rango tienen un prefijo común, y cada dirección con ese prefijo está a su vez dentro del rango. Por ejemplo, a una organización europea que requiera 1500 direcciones IP se le asignarían 8 números de red de clase C(2048 direcciones IP) del espacio reservado para redes europeas (194.0.0 a 195.255.255) y el primero de estos números de red sería divisible por ocho. Un rango de direcciones que se adecuase a esta regla sería el 194.32.136 - 194.32.143, en cuyo caso contendría todas las direcciones IP con el prefijo de 21 bits 194.32.136, o '110000100010000010001'. El número máximo de números de red asignados contiguamente es 64, correspondiente a un prefijo de 18 bits. Una organización que requiera más de 4096 direcciones pero menos de 16,384 puede solicitar tanto una clase B como un rango de direcciones de clase C. En general, el número de clases C asignadas es el mínimo necesario para proporcionar la cantidad requerida de direcciones IP a la organización partiendo de una previsión sobre el plazo de los dos años siguientes. Sin embargo, en algunos casos, una organización puede solicitar múltiples redes que sean tratadas por separado. Por ejemplo, a una organización con 600 hosts se le asignarían normalmente 4 redes de clase C. No obstante, si esos hosts estuvieran distribuidos a lo largo de 10 LANs en anillo con testigo con entre 50 y 70 hosts por LAN, tal esquema de direcciones causaría graves problemas, ya que la organización tendría que encontrar 10 subredes dentro de un rango de direcciones locales de 10 bits. Esto significaría que al menos alguna de las LAN tendría una máscara de subred de 255.255.255.192, que sólo permite 62 hosts por LAN. La intención de las reglas no es forzar a la organización a que tenga un complicado sistema de subredes, así que la organización debería solicitar 10 números de clase C diferentes, uno para cada LAN. Las reglas actuales se pueden encontrar en el RFC 1466 - Directrices para la gestión del espacio de direcciones IP. Las razones de las reglas de distribución de los números de red de clase C quedarán patentes en la próxima sección. Usar números de clase C de esta forma ha frenado el problema del agotamiento de las direcciones de clase B, pero no es una solución definitiva a las limitaciones de espacio inherentes a IP. La solución a largo plazo se discute en IP: La próxima generación(IPng). 2.2.6 Redes privadas Otro enfoque de la conservación del espacio de direcciones IP se describe en el RFC 1597 - Distribución de direcciones para redes privadas. En pocas palabras, relaja la regla de que las direcciones IP han de ser unívocas globalmente al reservar parte del espacio de direcciones para redes que se usan exclusivamente dentro de una sola organización y que no requieren conectividad IP con Internet. Hay tres rangos de direcciones que IANA ha reservado con este propósito: * 10 Una sola red de clase A * 16 redes clase B contiguas del 172.16 al 172.31 * 256 redes clase C contiguas del 192.168.0 al 192.168.255 Cualquier organización puede usar cualquier dirección en estos rangos si no hace referencia a ninguna otra organización. Sin embargo, debido a que estas direcciones no son unívocas a nivel global, no pueden ser direccionadas por hosts de otras organizaciones y no están definidas para los "routers" externos. Se supone que los "routers" de una red que no usa direcciones privadas, particularmente aquellos operados por proveedores de servicios de Internet, han de desechar toda información de encaminamiento relativa a estas direcciones. Los "router" de una organización que utiliza direcciones privadas deberían limitar todas las referencias a direcciones privadas a los enlaces internos; no deberían hacer públicas las rutas a direcciones privadas ni enviar datagramas IP con estar direcciones a los "routers" externos. Los hosts que sólo tienen una dirección IP privada carecen de conexión IP con Internet. Esto puede ser deseable y a lo mejor puede ser una razón para emplear direcccionamiento privado. Toda la conectividad con host externos de Internet la deben proporcionar pasarelas de aplicación. 2.2.7 CIDR("Classless Inter-Domain Routing" El uso de un rango de direcciones de clase C en vez de una sola de clase B acarrea un gran problema: cada red ha de ser direccionada por separado. El encaminamiento IP estándar sólo comprende las clases A, B y C. Dentro de cada uno de estos tipos de red, se puede usar "subnetting" para proporcionar mejor granularidad del espacio de direcciones en cada red, pero no hay forma de especificar que existe una relación real entre múltiples redes de clase C. El resultado de esto se denomina el problema de la explosión de la tabla de encaminamiento: una red de clase B de 3000 host requiere una entrada en la tabla de encaminamiento para cada "router" troncal, pero si la misma red se direccionase como un rango de redes de clase C, requeriría 16 entradas. La solución a este problema es un método llamado CIDR("Classless Inter-Domain Routing". El CIDR es un protocolo propuesto como estándar con status electivo. El CIDR no encamina de acuerdo a la clase del número de red(de ahí el término "classless": sin clase) sino sólo según los bits de orden superior de la dirección IP, que se denominan prefijo IP. Cada entrada de encaminamiento CIDR contiene una dirección IP de 32 bits y una máscara de red de 32 bits, que en conjunto dan la longitud y valor del prefijo IP. Esto se puede representar como <dir_IP máscara_red. Por ejemplo, <194.0.0.0 254.0.0.0 representa el prefijo de 7 bits B'1100001'. CIDR maneja el encaminamiento para un grupo de redes con un prefijo común con una sola entrada de encaminamiento. Esta es la razón por la que múltiples números de red de clase C asignados a una sola organización tienen un prefijo común. Al proceso de combinar múltiples redes en una sola entrada se le llama agregación de direcciones o reducción de direcciones. También se le llama supernetting poque el encaminamiento se basa en máscaras de red más cortas que la máscara de red natural de la dirección IP, en contraste con el subnetting, donde las máscaras de red son más largas que la máscara natural. A diferencia de las máscaras de subred, que normalmente son contiguas pero pueden tener una parte local no contigua, las máscaras de superred son siempre contiguas Si se representan las direcciones IP con una árbol que muestre la topología de encaminamiento, donde cada hoja del árbol significa un grupo de redes que se consideran como una sola unidad(llamada dominio de encaminamiento) y el esquema de direccionamiento IP se elige de modo que cada bifurcación del árbol corresponda a un incremento en la longitud del prefijo IP, entonces el CIDR permite realizar la agregación de direcciones muy eficientemente. Por ejemplo, si un "router" en Norteamérica encamina todo el tráfico europeo a través de un único enlace, entonces una sola entrada de encaminamiento para <194.0.0.0 254.0.0.0 incluye el grupo de direcciones de redes de clase C asignadas a Europa como se describe más arriba. Esta única entrada toma el lugar de todas las entradas de los números de red asignados, que son un máximo de 2exp17, o 131,072. En el extremo europeo del enlace, hay entradas de encaminamiento con prefijos más largos que mapean la topología de la red europea, pero esta información de encaminamiento no hace falta en el extremo americano. La filosofía de CIDR es "la mejor aproximación es la que tiene más aciertos", de modo que si los US necesitan hacer una excepción para un rango de direcciones, como por ejemplo las 64 redes <195.1.64.0 255.555.192.0, necesita sólo una entrada adicional, que en la tala de encaminamiento se superpone a otras entradas más generales(más cortas) de las redes que contiene. De este ejemplo se hace evidente que a medida que aumenta el uso del espacio de direcciones IP, particularmente de las de clase C, los beneficios de CIDR aumentan por igual, siempre que la asignación de direcciones siga la topología de la red. El estado actual del espacio de direcciones IP no sigue este esquema ya que el desarrollo de CIDR fue posterior. Sin embargo, se están asignando nuevas direcciones de clase C de tal modo que sean compatibles con CIDR, lo que debería tener el efecto de aliviar el problema de la explosión de las tablas de encaminamiento a corto plazo. A largo plazo, puede que sea necesaria una reestructuración del espacio de direcciones IP siguiendo pautas topológicas. Esto supondría tener que renumerar un gran número de redes, implicando un enorme trabajo de implementación, por lo que se trataría de un proceso gradual Asumir que la topología de encaminamiento se puede representar con un simple árbol es un exceso de simplificación; aunque la mayoría de los dominios de encaminamiento tienen un sólo enlace que proporciona acceso al resto de Internet, hay también muchos dominios con enlaces múltiples. Los dominios de encaminamiento de estos dos tipos se llaman "single-homed"(unipuerto) y "multi-homed"(multipuerto). Es más, la topología no es estática. No sólo se unen nuevas organizaciones a un ritmo creciente, sino que las ya existentes pueden cambiar partes de su topología, por ejemplo, si cambian de proveedor de servicios por razones comerciales o de otra índole. Aunque estos casos complican la implementación práctica del encaminamiento basado en CIDR y reducen la eficiencia de la agregación de direcciones que se puede conseguir, la estrategia no deja de ser válida. Las políticas actuales para la distribución de direcciones de Internet y las suposiciones en las que se basan se describen en el RFC 1518 - Una arquitectura para la distribución de direcciones IP con CIDR. Se pueden resumir en: * La asignación de direcciones IP refleja la topología física de la red y no de la organización; las restricciones organizacionales y administrativas no deberían usarse en la asignación de direcciones IP cuando no se ajusten a la topología de la red. * En general, la topología de la red seguirá de cerca los límites continentales y nacionales, y por tanto las direcciones IP se deberían asignar partiendo de esta base. * Habrá un número relativamente pequeño de redes que transportarán una elevada cantidad de tráfico entre dominios de encaminamiento y que estarán conectadas de modo no jerárquico, traspasando los límites nacionales. Estas redes se denominan TRDst("Transit Routing Domains". Cada TRD tendrá un prefijo IP unívoco. En general, los TRDs no se organizarán jerárquicamente. Sin embargo, cuando un TRD se halle por completo dentro de los límites contientales, su prefijo IP debería ser una extensión del prefijo IP continental. * Habrá organizaciones con enlaces a otras organizaciones que son para su uso privado y que no transportarán tráfico dirigido a otros dominios(tráfico de tránsito). Estas conexiones privadas no tienen un efecto significativo sobre la topología de red y pueden ser ignoradas. * La gran mayoría de los dominios de encaminamiento serán single-homed. Es decir, estarán conectadas a un sólo TDR. Se les debería asignar direcciones que comiencen por el prefijo IP de ese TRD. Por tanto, todas las direcciones de los dominios "single-homed" conectados a un TDR se pueden agregar en una sola entrada de la tabla de encaminamiento para todos los dominios externos a ese TRD. Nota: Esto implica que si una organización cambia su proveedor de servicios de Internet, debería cambiar todas sus direcciones IP. Esto no es lo habitual, pero es probable que la difusión de CIDR lo convierta en una práctica mucho más común. * Hay una serie de esquemas de asignación de direcciones que se pueden usar con dominios "multi-homed". Algunos son: o El uso de un único prefijo IP para el dominio. Los "routers" externos deben tener una entrada para la organización que se halla parcial o totalmente fuera de la jerarquía normal. Donde un dominio sea "multi-homed", pero todos los TRDs conectados estén topológicamente cerca, sería apropiado que el prefijo IP del dominio incluyese los bits comunes a todos los TRDs conectados. Por ejemplo, si todos los TRDs estuvieran totalmente dentro de los Estados Unidos, un prefijo IP indicando exclusivamente un dominio de Norteamérica sería lo adecuado. o El uso de un prefijo IP para cada TRD conectado, con hosts en el dominio que tengan direcciones IP que contengan el prefijo del TRD más apropiado. La organización da la impresión de ser un conjunto de dominios de encaminamiento. o Asignar un prefijo IP de uno de los TRDs conectados. Este TRD se convierte en un TRD por defecto para el dominio, aunque otros dominios pueden encaminar explícitamente sus mensajes por uno de los TRDs alternativos. o El uso de prefijos IP para referirse a conjuntos de dominios "multi-homed" con conexiones a TRDs. Por ejemplo, puede haber un prefijo IP que se refiera a dominios "single-homed" conectados a la red A, uno que se refiera a dominios "single-homed" conectados a la red B y uno para los dominios conectados a A y a B. * Cada uno de estos esquemas tiene sus ventajas, desventajas y efectos colaterales. Por ejemplo, el primero tiende a generar un tráfico interno en el dominio receptor más cercano al host fuente superior al generado por el segundo esquema, aumentando recursos de red consumidos en la organización receptora. Debido a que los dominios "multi-homed" varían mucho en su carácter y ninguno de los esquemas anteriores parece apropiado para todos, no existe una política que sea la mejor, y el RFC 1518 no especifica ninguna regla para elegir entre ellas. 2.2.7.1 Implementación de CIDR La implementación de CIDR en Internet se basa fundamentalmente en BGP("Border Gateway Protocol", versión 4) (ver BGP-4("Border Gateway Protocol", versión 4)). En el futuro CIDR también se implementará con una variante del estándar ISO IDRP, ISO 10747("Inter-Domain Routing Protocol", llamado IDRP para IP, que está estrechamente relacionado con BGP-4. La estrategia de implementación, descrita en el RFC 1520 - Intercambiando información de encaminamiento a través de las fronteras de los proveedores en el entorno CIDR, implica un proceso por fases a través de la jerarquía de encaminamiento, empezando por los "routers" troncales. Los proveedores de servicios de red se dividen en cuatro tipos: Tipo 1 Aquellos que no pueden emplear ningún IDRP. Tipo 2 Aquellos que usan IDRP por defecto pero que requieren rutas explícitas para una proporción considerable de los números IP de red asignados. Tipo 3 Aquellos que usan IDRP por defecto y añaden además un pequeño número de rutas explícitas. Tipo 4 Aquellos que ejecutan IDRP utilizando sólo rutas por defecto. La implementación de CIDR implica una primera fase por medio de los proveedores de tipo 0, luego los de tipo 2 y finalmente los de tipo 3. CIDR ya se ha instituido ampliamente en troncales y más de 9000 rutas se han reemplazado por aproximadamente 2000 rutas CIDR. 2.2.7.2 Referencias * RFC 1467 - Difusión de CIDR en Internet * RFC 1517 - Condiciones de aplicabilidad de CIDR * RFC 1518 - Una arquitectura para la distribución de direcciones IP con CIDR * RFC 1519 - CIDR: asignación de direcciones y estrategia de agregación * RFC 1520 -Intercambiando información de encaminamiento a través de las fronteras de los proveedores en el entorno CIDR 2.2.8 DNS("Domain Name System" El protocolo DNS es un protocolo estándar (STD 13). Su status es recomendado. Es descrito en: * RFC 1034 - Nombres de dominio - conceptos y servicios * RFC 1035 - Nombres de dominio - implementación y especificación Las configuraciones iniciales de Internet requerían que los usuarios emplearan sólo direcciones IP numéricas. Esto evolucionó hacia el uso de nombres de host simbólicos muy rápidamente. Por ejemplo, en vez de escribir TELNET 128.12.7.14, se podría escribir TELNET eduvm9, y eduvm9 se traduciría de alguna forma a la dirección IP 128.12.7.14. Esto introduce el problema de mantener la correspondencia entre direcciones IP y nombres de máquina de alto nivel de forma coordinada y centralizada. Inicialmente, el NIC("Network Information Center" mantenía el mapeado de nombres a direcciones en un sólo fichero(HOSTS.TXT) que todos los hosts obtenían vía FTP. Se denominó espacio de nombres plano. Debido al crecimiento explosivo del número de hosts, este mecanismo se volvió demasiado tosco(considerar el trabajo necesario sólo para añadir un host a Internet) y fue sustituido por un nuevo concepto: DNS("Domain Name System". Los hosts pueden seguir usando un espacio de nombres local plano(el fichero HOSTS.LOCAL) en vez o además del DNS, pero fuera de redes pequeñas, el DNS es prácticamente esencial. El DNS permite que un programa ejecutándose en un host le haga a otro host el mapeo de un nombre simbólico de nivel superior a una dirección IP, sin que sea necesario que cada host tenga una base de datos completa de los nombres simbólicos y las direcciones IP. En el resto de esta sección examinaremos cómo funciona el DNS desde el punto de vista del usuario. Ver DNS("Domain Name System" para más detalles sobre la implementación y los tipos de datos almacenados en DNS. 2.2.8.1 El espacio de nombres jerárquico Consideremos la estructura interna de una gran organización. Como el jefe no lo puede hacer todo, la organización tendrá que partirse seguramente en divisiones, cada una de ellas autónoma dentro de ciertos límites. Específicamente, el ejecutivo a cargo de una división tiene autoridad para tomar decisiones sin requerir el permiso de su jefe. Los nombres de dominio se forman de modo similar, y con frecuencia reflejarán la delegación jerárquica de autoridades usada para asignarlos. Por ejemplo, considerar el nombre lcs.mit.edu Aquí, lcs.mit.edu es el nombre de dominio de nivel inferior, un subdominio de mit.edu, que a su vez es un subdominio de edu("education", conocido como dominio raíz. También podemos representar este forma de asignar nombres con un árbol jerárquico,(ver Figura - Espacio de nombres jerárquico). Figura: Espacio de nombres jerárquico - Esta figura muestra la cadena de autoridades en la asignación de nombres de dominio. Este árbol es sólo una fracción mínima del espacio de nombres real. Figura - Los dominios genéricos de la cima muestra algunos de los dominios de la cima. El dominio único que se halla sobre la cima no tiene nombre y se le conoce como dominio raíz. La estructura completa se explica en las siguientes secciones. 2.2.8.2 FQDNs("Fully Qualified Domain Names" Cuando se usa el DNS, es común trabajar con sólo una parte de la jerarquía de dominios, por ejemplo el dominio ral.ibm.com. El DNS proporciona un método sencillo para minimizar la cantidad de caracteres a escribir en estos casos. Si el nombre de dominio termina en un punto(por ejemplo wtscpok.itsc.pok.ibm.com.) se asume que está completo. Es lo que se llama un FQDN("Fully Qualified Domain Name" o nombre absoluto de dominio. Si, sin embargo, no termina en punto,(por ejemplo wtscpok.itsc) estará incompleto y procesador de nombres del DNS, como se verá más abajo, podrá completarlo, por ejemplo, añadiendo un sufijo como .pok.ibm.com al nombre de dominio. Las reglas para hacer esto dependen de la implementación y son configurables localmente. 2.2.8.3 Dominios genéricos A los tres dominios de la cima se les llama dominios genéricos u organizacionales. Nombre de dominio Significado edu Instituciones educativas gov Instituciones gubernamentales com Organizaciones comerciales mil Grupos militares net Redes int Organizaciones internacionales org Otras organizaciones Figura: Los dominios genéricos de la cima Puesto que Internet comenzó en los Estados Unidos, la estructura del espacio de nombres jerárquico tenía inicialmente sólo organizaciones estadounidenses en la cima de la jerarquía, y sigue siendo cierto que gran parte de las organizaciones de la cima de la jerarquía son estadounidenses. Sin embargo, sólo los dominios .gov y .mil están restringidos a los US. 2.2.8.4 Dominios de países Además hay dominios de nivel de cima para cada uno de los códigos internacionales de dos caracteres ISO 3166 para países(de ae para los Emiratos Árabes Unidos a zw para Zimbabwe). Se les conoce como dominios de países o dominios geográficos. Muchos países tienen sus propios dominios de segundo nivel por debajo, paralelamente a los dominios genéricos. Por ejemplo, en el Reino Unido, los dominios equivalentes a .com y .edu son .co.uk y .ac.uk("ac" es la abreviatura de "academic". Está también el dominio .us, organizado geográficamente por estados(por ejemplo, .ny.us se refiere al estado de New York). Ver el RFC 1480 para una descripción detallada del dominio .us. 2.2.8.5 Mapeando nombres de dominio a direcciones IP El mapeado de nombres a direcciones, proceso denominado resolución de nombres de dominio, lo proporcionan sistemas independientes cooperativos, llamados servidores de nombres. Un servidor de nombres es un programa servidor que responde a peticiones de un cliente llamado procesador de nombres. Cada procesador de nombres está configurado con el nombre del servidor que va a usar(y posiblemente una lista de servidores alternativos con los que contactar si el servidor primario no está disponible). Figura - Resolución de nombres de dominio muestra esquemáticamente cómo un programa utiliza un procesador de nombres para convertir el nombre de un host en una dirección IP. El usuario proporciona el nombre de un host, y al programa de usuario emplea una rutina de librería, llamada stub, para comunicarse con un servidor de nombres que resuelve el nombre del host en una dirección IP y se la devuelve al stub, que a su vez lo devuelve al programa principal. El servidor de nombres pude obtener la respuesta de su caché de nombres, su propia base de datos o cualquier otro servidor de nombres. Figura: Resolución de nombres de dominio 2.2.8.6 Mapeando direcciones IP a nombres de dominio - Consultas con punteros El DNS suministra el mapeado de nombres simbólicos a direcciones IP y vice versa. Mientras que en principio es algo sencillo buscar en la base de datos una dirección IP, dado su nombre simbólico, el proceso inverso no se puede hacer respetando la jerarquía. Por este motivo, existe otro espacio de nombres para el mapeado inverso. Se halla en el dominio in-addr.arpa ("arpa" porque Internet era originalmente la red de ARPA). Como las direcciones IP suelen escribirse en formato decimal con puntos, hay una capa de dominios para cada jerarquía. Sin embargo, debido a que los nombres de dominio tienen primero la parte menos significativa del nombre y el formato decimal con puntos los bytes más significativos primero, la dirección decimal se muestra en orden inverso. Por ejemplo, el dominio del DNS correspondiente a la dirección IP 129.34.139.30 es 30.139.34.129.in-addr.arpa. Dada una dirección IP, el DNS puede utilizarse para encontrar el nombre del host que sea su pareja. Una consulta de nombre de dominio para encontrar los nombres del host asociado a una dirección IP se llama "consulta con puntero". 2.2.8.7 Otros usos para el DNS EL DNS está designado para ser capaz de almacenar una gran cantidad de información. Una de las más importantes es información del intercambio de correo, usada para el encaminamiento del correo electrónico. Esto aporta dos servicios: transparencia al reencaminar el correo a un host distinto del especificado y la implementación de pasarelas de correo, que pueden recibir correo electrónico y redirigirlo usando un protocolo diferente de aquel con el que lo reciben. Para más detalles, remitirse a SMTP y el DNS. 2.2.8.8 Referencias Para más detalles sobre la implementación del DNS y el formato de mensajes entre servidores de nombres, ver DNS("Domain Name System". Los siguientes RFCs definen el estándar de DNS y la información que almacena. * RFC 1032 - Guía de administrador de DNS * RFC 1033 - Guía de las operaciones de administrador de DNS * RFC 1034 - Nombres de dominio - Conceptos y servicios * RFC 1035 - Nombres de dominio - Implementación y especificación * RFC 1101 - Codificación DNS de nombres de red y de otros tipos * RFC 1183 - Nuevas definiciones del DNS RR * RFC 1706 - Registros de recursos DNS NSAP Parte 4 prontoo <a href='http://b.t.net.ar/www/delivery/ck.php?n=a2afc290&cb=INSERT_RANDOM_NUMBER_HERE' target='_blank'><img src='http://b.t.net.ar/www/delivery/avw.php?zoneid=58&cb=INSERT_RANDOM_NUMBER_HERE&n=a2afc290' border='0' alt='' /></a>

Registrate y eliminá la publicidad! 1.1 Introducción Las redes se han convertido en una parte fundamental, si no la más importante, de los actuales sistemas de información. Constituyen el pilar en el uso compartido de la información en empresas así como en grupos gubernamentales y científicos. Esta información puede adoptar distintas formas, sea como documentos, datos a ser procesados por otro ordenador, ficheros enviados a colegas, e incluso formas más exóticas de datos. La mayoría de estas redes se instalaron a finales de los años 60 y 70, cuando el diseño de redes se consideraba como la piedra filosofal de la investigación informática y la tecnología punta. Dio lugar a numerosos modelos de redes como la tecnología de conmutación de paquetes, redes de área local con detección de colisión, redes jerárquicas en empresas, y muchas otras de elevada calidad. Desde comienzos de los '70, otro aspecto de la tecnología de redes cobró importancia: el modelo de pila de protocolo, que permite la interoperabilidad entre aplicaciones. Toda una gama de arquitecturas fue propuesta e implementada por diversos equipos de investigación y fabricantes de ordenadores. El resultado de todos estos conocimientos tan prácticos es que hoy en día cualquier grupo de usuarios puede hallar una red física y una arquitectura adecuada a sus necesidades específicas, desde líneas asíncronas de bajo coste, sin otro método de recuperación de errores que una función de paridad bit a bit, pasando por funciones completas de redes de área extensa(pública o privada) con protocolos fiables como redes públicas de conmutación de paquetes o redes privadas SNA, hasta las redes de área local, de alta velocidad pero distancia limitada. El lado negativo de esta explosión de la información es la penosa situación que se produce cuando un grupo de usuarios desea extender su sistema informático a otro grupo de usuarios, que resulta que tiene una tecnología y unos protocolos de red diferentes. En consecuencia, aunque pudieran ponerse de acuerdo en el tipo de tecnología de red para conectar físicamente sus instalaciones, las aplicaciones(como por ejemplo sistemas de correo) serían aún incapaces de comunicarse entre sí debido a los diferentes protocolos. Se tomó conciencia de esta situación bastante temprano(a comienzo de los '70), gracias a un grupo de investigadores en los Estados Unidos, que fueron artífices de un nuevo paradigma: la interconexión de redes. Otras organizaciones oficiales se implicaron en la interconexión de redes, tales como ITU-T e ISO. Todas trataban de definir un conjunto de protocolos, distribuidos en un conjunto bien definido de capas, de modo que las aplicaciones pudieran comunicarse entre sí, con independencia de la tecnología de red subyacente y del sistema operativo sobre el que se ejecutaba cada aplicación. 1.2 Interredes Los diseñadores originales de la pila de protocolos ARPANET, subvencionados por DARPA ("Defense Advanced Research Projects Agency"introdujeron conceptos fundamentales tales como la estructura de capas y el de virtualidad en el mundo de las redes, bastante antes de que ISO se interesase en las redes. El organismo oficial de esos investigadores fue el grupo de trabajo en red ("Network Working Group" llamado ARPANET, que tuvo su última reunión general en octubre de 1071. DARPA ha continuado su investigación en busca de una pila de protocolos de red, desde el protocolo host-a-host NCP("Network Control Program" a la pila de protocolos TCP/IP, que adoptó la forma que tiene en la actualidad alrededor de 1978. En esa época, DARPA era un organismo famoso por ser pionero en la conmutación de paquetes a través de redes de radio y canales de satélite. La primera implementación real de Internet fue se produjo sobre 1980, cuando DARPA comenzó a convertir las máquinas de su red de trabajo(ARPANET) a los nuevos protocolos de TCP/IP. En 1983 la transición fue completa y DARPA exigió que todos los ordenadores que quisieran conectarse a ARPANET usaran TCP/IP. DARPA contrató además a Bolt, Beranek, y Newman (BNN) para desarrollar una implementación de los protocolos TCP/IP para el UNIX de Berkeley sobre el VAX y dotaron a la Universidad de California en Berkeley para que distribuyese ese código de modo gratuito con su sistema operativo UNIX. El primer lanzamiento de la distribución del sistema de Berkeley que incluyó el protocolo TCP/IP estuvo disponible en 1983(BSD 4.2). Desde ese momento, TCP/IP se ha difundido rápidamente entre universidades y centros de investigación y se ha convertido en el estándar de subsistemas de comunicación basados en UNIX. El segundo lanzamiento(BSD 4.3) se distribuyó en 1986, que es actualizado en 1988 (BSD 4.3 Tahoe) y en 1990 (BSD 4.3 Reno). BSD 4.4 fue distribuido en 1993. Debido a limitaciones de fondos, el BSD 4.4 será la última distribución que hará el grupo de investigación de sistemas informáticos("Computer Systems Research Group" de la Universidad de California en Berkeley. A medida que TCP/IP se extendía rápidamente, nuevas WANs se fueron creando y uniendo a ARPANET en los Estados Unidos. Por otro lado, redes de otros tipos, no necesariamente basadas en TCP/IP, se añadieron al conjunto de redes interconectadas. El resultado fue lo que hoy se conoce como Internet. Distintos ejemplos de redes que han jugado papeles clave en este desarrollo se describen en las siguientes secciones. 1.2.1 Internet ¿Qué es exactamente? En primer lugar, la palabra Internet es simplemente una contracción de la frase red interconectada. Sin embargo, escrita con mayúscula hace referencia a un conjunto mundial de redes interconectadas, de tal forma que Internet es una red interconectada, aunque no a la inversa. A Internet se le llama a veces "Interred conectada"("connected Internet". Internet está constituida por los siguientes grupos de redes(ver las siguientes secciones para más información): * Troncales: grandes redes que existen principalmente para interconectar otras redes. Actualmente las redes troncales son NSFNET en US, EBONE en Europa y las grandes redes troncales comerciales. * Redes regionales que conectan, por ejemplo, universidades y colegios. * Redes comerciales que suministran acceso a troncales y suscriptores, y redes propiedad de organizaciones comerciales para uso interno que también tienen conexión con Internet. * Redes locales, como por ejemplo, redes a nivel de campus universitario. En muchos casos, particularmente en redes de tipo comercial, militar y gubernamental, el tráfico entre estas y el resto de Internet está restringido(ver Cortafuegos("firewalls"). Esto conduce a la pregunta ¿Cómo sé si estoy conectado a Internet? Un enfoque viable es preguntarse: ¿puedo hacer un ping al host ds.internic.net? El ping, descrito en Ping, es un programa usado para determinar si un host de una red es alcanzable; está implementado en cualquier plataforma TCP/IP. Si la respuesta es no, entonces no estás conectado. Esta definición no implica necesariamente que uno esté totalmente aislado de Internet: muchos sistemas que fallarían en este test tienen, por ejemplo, pasarelas de correo electrónico a Internet. 1.2.2 ARPANET Llamado a veces el "abuelito" de las redes de conmutación de paquetes, ARPANET fue construido por DARPA(llamado ARPA en esa época) a finales de los '60 para facilitar la instalación de equipo de investigación de la tecnología de conmutación de paquetes y para permitir compartir recursos a los contratistas del Departamento de Defensa. La red interconectaba centros de investigación, algunas bases militares y emplazamientos gubernamentales. Pronto se popularizó entre los investigadores mediante la colaboración a través del correo electrónico y de otros servicios. Se desarrolló orientada a una utilidad para la investigación, usada por el DCA("Defense Communications Agency" a finales de 1975 y se dividió en 1983 en MILNET, para la interconexión de localizaciones militares, y ARPANET, para la interconexión de centros de investigación. Esto fue el primer paso hacia la "I" mayúscula de Internet. En 1974, ARPANET estaba basada en líneas arrendadas de 56kbps que interconectaban nodos de conmutación de paquetes(PSN) dispersados por todo US y el oeste de Europa. Eran minicomputadores que ejecutaban un protocolo conocido como1822 (por el número del informe que lo describía) y dedicados a la tarea de conmutación de paquetes. Cada PSN tenía al menos dos conexiones con otros PSNs(para permitir encaminamiento alternativo en caso de fallo de algún circuito)y hasta 22 puertos para conexiones de ordenadores de usuarios(hosts). Los sistemas 1822 permitían la entrega fiable y con control de flujo de un paquete al nodo de destino. Esta es la razón por la que el protocolo NCP original fue un protocolo bastante simple. Fue sustituido por los protocolos de TCP/IP, que no asumen la fiabilidad del hardware de red subyacente y pueden ser usados en redes distintas de las basadas en 1822. El 1822 no se convirtió en un estándar de la industria, por lo que posteriormente DARPA decidió reemplazar la tecnología de conmutación de paquetes del 1822 por el estándar CCITT X.25. El tráfico de datos excedió pronto la capacidad de las líneas de 56Kbps que constituían la red, que ya no eran capaces de soportar el flujo requerido. Hoy en día ARPANET ha sido sustituido por las nuevas tecnologías en su papel de troncal en el área de la investigación de Internet(ver NSFNET posteriormente, en este capítulo), mientras que MILNET sigue siendo la red troncal en el área militar. 1.2.3 NSFNET NSFNET("National Science Foundation Network", es una red de tres niveles situada en los Estados Unidos y consistente en: * Una troncal: una red que conecta redes de nivel medio administradas y operadas por separado y centros de superordenadores fundados por el NSF. Esta troncal tiene además enlaces transcontinentales con otras redes como por ejemplo EBONE, la red troncal europea de IP. * Redes de nivel medio: de tres clases(regionales, basadas en una disciplina y redes formadas por un consorcio de superordenadores). * Redes de campus: tanto académicas como comerciales, conectadas a las de nivel medio. La primera troncal. Establecida originalmente por el NSF("National Science Foundation" como una red de comunicaciones para investigadores y científicos para acceder a los superordenadores del NSF, la primera troncal de NSFNET usaba seis microordenadores DEC LSI/11 como conmutadores de paquetes, interconectados por líneas arrendadas de 56Kbps. Existía una interconexión primaria entre la troncal de NSFNET y ARPANET en el Carnegie Mellon, que permitía el encaminamiento de datagramas entre usuarios conectados a esas redes. La segunda troncal. La necesidad de una nueva troncal se manifestó en 1987, cuando la primera quedó sobrecargada en pocos meses(el crecimiento estimado en ese momento fue de un 100% anual). El NSF y MERIT, Inc., un consorcio de redes de ordenadores de ocho universidades estatales de Michigan, acordaron desarrollar y gestionar una nueva troncal de alta velocidad con mayores capacidades de transmisión y de conmutación. Para gestionarla definieron el IS ("Information Services" que está compuesto del Centro de Información y el Grupo de Soporte Técnico. El Centro de Información es responsable de distribuir información, la gestión de recursos informativos y la comunicación electrónica. El grupo de soporte técnico proporciona apoyo técnico directamente sobre el campo de trabajo. El propósito de esto es suministrar un sistema integrado de información con interfaces fáciles de usar y administrar, accesible desde cualquier punto de la red y apoyado por toda una serie de servicios de formación. MERIT y NSF dirigieron este proyecto con IBM y MCI. IBM proporcionó el software, equipo para la conmutación de paquetes y la gestión de redes, mientras que MCI aportó la infraestructura para el transporte a largas distancias. Instalada en 1988, la nueva red usaba inicialmente circuitos arrendados de 448Kbps para interconectar 13 sistemas nodales de conmutación(NSS) suministrados por IBM. Cada NSS estaba compuesto de nueve sistemas RT de IBM(que usaban una versión IBM del BSD 4.3) conectados a través de dos redes en anillo de IBM(por redundancia). En cada una de las 13 localizaciones se instaló un IDN"Integrated Digital Network Exchange" de IBM, para permitir: o Encaminamiento dinámico alternativo o Reserva dinámica de ancho de banda La tercera troncal En 1989, la topología de los circuitos de NFSNET fue reconfigurada después de haber medido el tráfico y la velocidad de las líneas arrendadas se incrementó a T1(1.544Mbps) usando principalmente fibra óptica. Debido a la necesidad constantemente creciente de mejoras en la conmutación de paquetes y en la transmisión, se añadieron tres NSSs a la troncal y se actualizó la velocidad de las conexiones. La migración de NFSNET de T1 a T3(45Mbps) se completo a finales de 1992. Advanced Network & Services, Inc. (compañía fundada por IBM, MCI, Merit, Inc.) es en la actualidad el organismo proveedor y gestor de NFSNET. La migración a niveles de gigabits ya ha empezado y continuará durante finales de l990. Para más información, remitirse a Futuro. El gobierno de US pretende retirar sus fondos de NSFNET en abril de 1995. Esto es parte de una reacción ante el uso comercial de NSFNET. Para más detalles sobre este tema, ver Uso comercial de Internet y La super autopista de la información respectivamente. 1.2.4 EBONE EBONE,("Pan-European Multi-Protocol Backbone" juega en el tráfico de Internet en Europa el mismo papel que NSFNET en US. EBONE tiene conexiones a nivel de kilobit y megabit entre cinco grandes centros. 1.2.5 CREN Completado en octubre de 1989, el organismo fusionador de las dos famosas redes CSNET("Computer+Science Network" y BITNET("Because It's Time Network" formó el CREN("Corporation for Research and Educational Networking". CREN abarca la familia de servicios históricas de CSNET y BITNET para proporcionar una rica variedad de opciones en la conexión de redes: PhoneNet Es el servicio original de red de CSNET y proporciona servicio de correo electrónico "store-and-forward" usando líneas telefónicas de marcaje(1200/2400 bps). Permite a los usuarios intercambiar mensajes con otros miembros del CREN y de otras grandes redes de correo, incluyendo a NSFNET, MILNET, etc. X.25Net Es un red de CSNET conectada a Iternet que suministra un servicio completo, usa protocolo TCP/IP sobre X.25. Es habitual que los miembros internacionales se conecten a CSNET, ya que pueden usar su red pública de datos("Public Data Network" X.25 para alcanzar a Telenet en US. Aporta transferencia de ficheros, telnet, así como servicio inmediato de correo electrónico entre host de X.25Net. IP de marcaje Es una implementación de SLIP("Serial Line IP" que permite que los sitios que usan la red telefónica conmutada(9600bps) envíen paquetes IP, por medio de un servidor central, a Internet. Los usuarios de este método tienen los mismos servicios que en X.25Net. Línea IP arrendada Usada por muchos miembros del CREN para conectarse a CREN. Soporta una serie de velocidades de enlace hasta tasas T1. RSCS/NJE sobre BISYNC Tradicionalmente funciona sobre líneas arrendadas a 9600bps y proporciona servicio de mensajes interactivos, transferencias de ficheros no solicitadas y correo electrónico. RSCS sobre IP Permite a los "hub" del servicio BITNET relajar las líneas dedicadas de RSCS BYSYNC en favor de una ruta IP, si existe. 1.2.6 Cypress Cypress es una red sobre líneas arrendadas que permite tener un sistema de conmutación de paquetes de bajo coste e independiente del protocolo, usado principalmente para interconectar sitios pequeños a redes de Internet sobre TCP/IP. Establecido en origen como parte de un proyecto de investigación conjunto con CSNET, ahora es independiente de CSNET. No hay restricciones sobre su uso, aparte de las impuestas por otras redes. De este modo el tráfico comercial puede pasar entre dos sitios industriales a través de Cypress. Los sitios industriales no pueden pasar tráfico comercial sobre Internet debido a restricciones impuestas por agencias gubernamentales que controlan las redes troncales (por ejemplo, NFSET). 1.2.7 DRI TWN("Terrestrial Wideband Network" o Red Terrestre de Banda Ancha es una WAN con el propósito de proporcionar una plataforma para la investigación con protocolos y aplicaciones en redes de alta velocidad(papel representado inicialmente por ARPANET). Este sistema incluye servicios tanto orientados a conexión como no orientados a conexión, broadcast y conferencia en tiempo real. La TWN fue construida y puesta en marcha por BNN Systems y Technologies Corporation durante la primera mitad de 1989 como parte de la fase inicial del DRI("Defense Research Internet". Su principal finalidad era transportar a lo largo y ancho del país el tráfico de datagramas asociado a proyectos subvencionados por DARPA. Estaba compuesto de pasarelas de Internet y conmutadores de paquetes WPSs("Terrestrial Wideband Network packet switches" que se comunicaban entre sí usando el HAP("Host Access Protocol" especificado en RFC 1221. Se usó el WB-MON("Wideband Monitoring Protocol" entre los WPSs y el centro de monitorización. La troncal soportaba también un entorno de investigación para conferencia multimedia y conferencia con voz y vídeo empleando pasarelas que utilizaban un protocolo orientado a conexión en tiempo real(ST-II - Stream Protocol - RFC 1190) sobre un red no orientada a conexión. 1.2.8 EARN("European Academic Research Network" EARN, iniciada en 1983, fue la primera y mayor red en dar servicio a instituciones académicas y de investigación en Europa, Oriente Medio y África. EARN comenzó su andadura con la ayuda de IBM. Evolucionó para convertirse en una red sin ánimo de lucro y basada en tráfico no comercial que da servicio a instituciones académicas y de investigación. 1.2.9 RARE("Réseaux Associés pour la Recherche" RARE, fundada en 1986, es la asociación de organizaciones de redes europeas y sus usuarios. La asociación tiene 20 FNM("Full National Members"; todos países europeos), numerosos ASN("Associate National Members"; algunos países europeos y asiáticos), IM("International Members"; por ejemplo EARN) y LM("Liason Members"; por ejemplo CREN). Soporta los principios de los sistemas abiertos tal como se definen en ISO además de un número de grupos principalmente europeos, como el EWOS ("European Workshop for Open Systems" y el ETSI ("European Telecommunications Standards Institute" . Para más detalles, remitirse a RARE("Réseaux Associés pour la Recherche Européenne". 1.2.10 RIPE("Réseaux IP Européens" El "Réseaux IP Européens"(RIPE) coordina las redes TCP/IP para la comunidad científica en Europa. Opera bajo los auspicios de RARE. RIPE lleva funcionando desde 1989. A comienzos de los '90 más de 60 organizaciones participaban en este trabajo. El objetivo de RIPE es asegurar la coordinación administrativa y técnica necesaria para permitir el funcionamiento de la red IP pan-Europea. Notar que RIPE no gestiona ninguna red de su propiedad. RIPE puede definirse como la actividad IP de RARE. Una de las actividades de RIPE es, mantener una base de datos de redes IP europeas, dominios DNS y sus contactos. El contenido de esta base de datos se considera de dominio público. La base de datos puede ser accedida vía un servidor WHOIS en el host whois.ripe.net (puerto TCP 43) o vía un FTP anónimo a ftp.ripe.net. El RIPE NCC ("Network Coordination Center" se puede conectar vía: RIPE NCC Kruislaan 409 NL-1098 SJ Amsterdam The Netherlands Phone: +31 20 592 5065 Fax: +31 20 592 5155 E-mail: ncc@ripe.net 1.2.11 Internet en Japón Japón tiene muchas redes distintas. Las siguientes son algunas de las principales. * La BITNET japonesa comenzó a funcionar en 1985. Fue fundada por la Universidad de la Ciencia de Tokyo y parte de sus miembros. Esta red conecta con CUNY ("City University of New York" a través de un enlace a 56 Kbps. * N-1net es gestionada por el NACSIS ("National Center for Science and Information Systems", un instituto de investigación fundado por el Ministerio de Educación de Japón. Empezó a funcionar en 1980 usando una red de conmutación de paquetes X.25. N-1net tiene una conexión de 50 Kbps con el NSF en Washington. * EL TISN("International Science Network" de Todai es usado por físicos y químicos. TISN tiene un enlace de 128 Kbps entre Todai y Hawaii. * WIDE("Widely Integrated Distributed Environment" es la versión japonesa de Internet. Comenzó como un proyecto de investigación en 1986. Hay dos conexiones entre WIDE y el resto de Internet. Uno, de 192 Kbps va de la Universidad de Keio en Fujisawa a la Universidad de Hawaii. El otro es un enlace secundario de 128 Kbps de Todai a Hawaii, previsto para el caso de que falle el principal. Para más detalles, remitirse a y listados en Bibliografía. 1.2.12 Uso comercial de Internet En años recientes Internet ha crecido en tamaño y extensión a una ritmo mayor de lo que nadie podría haber previsto. En particular, más de la mitad de los hosts conectados hoy a Internet son de carácter comercial. Esta es un área conflictiva, potencial y realmente, con los objetivos iniciales de Internet, que eran favorecer y cuidar del desarrollo de las comunicaciones abiertas entre instituciones académicas y de investigación. Sin embargo, el crecimiento continuado en el uso comercial de Internet es inevitable por lo que será útil explicar como está teniendo lugar esta evolución. Una iniciativa importante a tener en cuenta es la de AUP("Acceptable Use Policy". La primera de estas políticas se introdujo en 1992 y se aplica al uso de NSFNET. Una copia de ella se puede conseguir en nic.merit.edu/nsfnet/acceptable.use.policies. En el fondo AUP es un compromiso "para apoyar la investigación y la educación abierta". Bajo "usos inaceptables" está la prohibición de "uso para actividades lucrativas", a menos que se hallen incluidas en el Principio General o como un uso específico aceptable. Sin embargo, a pesar de estas instancias aparentemente restrictivas, NSFNET se ha ido usando cada vez más para un amplio abanico de actividades, incluyendo muchas de naturaleza comercial. Aparte del AUP de NSFNET, muchas de las redes conectadas a NSFNET mantienen sus propios AUPs. Algunos de ellos son relativamente restrictivos en su tratamiento de las actividades comerciales mientras que otros son relativamente liberales. Lo importante es que los AUP tendrán que evolucionar mientras continúe el inevitable crecimiento comercial en Internet. Concentrémonos ahora en los proveedores de servicios en Internet que han desarrollado mayor actividad en la introducción de usos comerciales de Internet. Dos dignos de mencionar son PSINet y UUNET, que a finales de los '80 comenzaron a ofrecer acceso a Internet tanto a negocios como a individuos. CERFnet, establecida en California, ofrece servicios libres de cualquier AUP. Poco después se formó una organización para unir PSINet, UUNet y CERFNet, llamada CI"Commercial Internet Exchange". Hasta la fecha CIX tiene más de 20 miembros que conectan las redes constituyentes en un entorno libre de AUPs. Sobre el mismo momento en que surgió CIX, una compañía sin ánimo de lucro, ANS("Advance Network and Services ", fue formada por IBM, MCI y Merit,Inc. con el fin de operar conexiones troncales T1 para NSFNT. Este grupo ha permanecido activo e incrementando su presencia comercial en Internet. ANS formó también una subsidiaria orientada comercialmente denominada ANS CO+RE para proporcionar enlaces entre clientes comerciales y dominios educacionales y de investigación. ANS CO+RE suministra además acceso libre de AUPs a NSFNET al estar conectada a CIX. 1.2.13 La super autopista de la información Una reciente e importante iniciativa ha sido la creación del Consejo Estadounidense de Asesoramiento sobre la Infraestructura Nacional de Información("US Advisory Council on the National Information Infrastructure" dirigido por Al Gore. En esencia, la iniciativa hace de la creación de una "red de redes" una prioridad nacional. Esta red debería ser similar a Internet en algunos aspectos, pero con el gobierno y la industria contribuyendo cada uno con lo mejor de sí mismo. Desde una perspectiva más internacional, el Grupo de los Siete("The Group of Seven(G7)" ministros se reunió en Bruselas en febrero de 1995 para discutir sobre la incipiente GII("Global Information Infrastructure". Los ministros de tecnología y economía de Canadá, el Reino Unido, Francia, Japón. Alemania, Italia, y los Estado Unidos acudieron a la conferencia, y se concentraron en las implicaciones tecnológicas, culturales y económicas concernientes al desarrollo de la infraestructura nacional. Una revista electrónica gratuita llamada G7 Live se utilizó para hacer llegar diariamente a los usuarios de Internet los comentarios y noticias sobre la conferencia. Aspectos específicos cubiertos por G7 Live incluyen los derechos de la propiedad intelectual, construcción de infraestructuras, consideraciones culturales y legislativas, y descripciones de las más de 100 exhibiciones tecnológicas presentes en la conferencia. Tanto el NII como el GII descritos anteriormente son iniciativas importantes que en última instancia deberían conducir a la "super autopista de la información" que es en la actualidad el objeto de tanta discusión en los medios de comunicación. 1.4 Futuro La perspectiva a largo plazo descrita en el HPCC ("United States Federal High Performance Computing and Communications Program" indica que todas las redes de Internet serán absorbida por el NREN ("National Research and Education Network". El HPCA("High Performance Computing Act" de 1991 fue legalizada en Estados Unidos en diciembre de 1991. Establecía un presupuestos de unos 100 millones de dólares anuales durante 5 años. El desarrollo de la red del programa NREN se ha orientado a sistemas de computación distribuidos para instituciones educativas y de investigación, así como a investigaciones en redes y aplicaciones de alta velocidad. NREN ya ha organizado la integración, en coordinación con el NSF, del DRI ("DoD's Defense Research Internet", NSFNet, la NASA ("National Aeronautics and Space Administration", el NSI("Science Internet", el DOE("Department of Energy" y Esnet("Energy Science Network". El programa NREN especifica un proyecto de tres fases dirigido por DARPA para incrementar la velocidad de transmisión de datos a 3 Gbps durante los próximos 10 – 15 años. Este programa también incluye la exploración de mecanismos de tasación de servicios de red y el comienzo de una transición estructurada a los servicios comerciales. En agosto de 1992, bajo el programa NREN, el DOE firmó un contrato de 5 años por valor de 50 millones de dólares con la Sprint Corporation para servicios públicos de ATM . En el momento de redactar este documento, la evolución de NREN en lo que respecta alas redes de alta velocidad es considerable. El NAP("Network Access Point" es un cambio importante de cara a la nueva arquitectura de Internet. El NSF ha escogido una serie de organizaciones para que operen el NAP. Entre ellas están: * Sprint Corporation - Nueva York/New Jersey * Ameritech - Chicago * PacBell - San Francisco/Bay Area * MFSdatanet - Washington DC El NSP("Network Service Provider" es un proveedor de servicios de Internet capacitado para disponer de conectividad local gracias al NSF. Esto significa que el NSP se debe conectar a tres NAPs primarios en California, Chicago y Nueva York. Entre estos se hallan: * ANS (ahora propiedad de America Online) * MCInet * SprintLink Además, hay un número de ISPs("Internet Service Providers" que no tienen esta conectividad local. Entre ellas están: * AlterNet * Net99 * PSI Un RA("Routing Arbitor" es una organización que recibe fondos del NSF y que proporciona información de encaminamiento a cada NAP. Los NAPs proporcionan actualmente servicios de alta velocidad basados en ATM, retransmisión de trama y FDDI a los NSPs y los ISPs. Para más información sobre estos NAPs, remitirse a http://rrdb.merit.edu/napsp3.html http://rrdb.merit.edu/pacbell.html. 1.4.1 Futuro – Redes de alta velocidad El futuro de NREN está influenciado, cuando menos, por los avances en la tecnología de redes de alta velocidad. * La retransmisión de tramas es un estándar de red que sirve de interfaz en redes orientadas a paquetes. Soporta tamaños de paquete variables, por lo que no está recomendado para el tráfico isócrono, como por ejemplo de voz o vídeo. Una red se puede implementar fácilmente con un equipo ya existente de conmutación de paquetes empleando la retransmisión de tramas para mejorar su rendimiento. La velocidad actual de esta tecnología es T - 1 (1.544 Mbps). * DQDB (Distributed Queue Dual Bus) es un protocolo diseñado para manejar tráfico tantro isócrono como de datos sobre enlaces de ópticos de alta velocidad. Los medios de transmisión definidos son: o Conexión de fibra a 35 Mbps y 155 Mbps o SONET (Synchronous Optical Network) a partir de 51,840 Mbps. Fue aceptado como estándar (IEEE 802.6) por las MANs ("Metropolitan Area Networks". * ATM (Asynchronous Transfer Mode), es una tecnología de conmutación basada en celdas de longitud fija de 53 bytes. Proporciona velocidades altas (definidas a 155 Mbps y 622 Mbps) y es adecuada para la transmisión de voz, vídeo y datos. No se espera que las redes públicas soporten ATM hasta finales de los ´90. * ISDN de banda ancha es un tecnología nueva, aunque no estandarizada, que ofrece velocidades incluso mayores, a partir de OC - 3 ("Optical Carrier level 3", 155.52 Mbps). No se espera que esté disponible hasta 1995, como pronto. 1.5 RFC("Request For Comments" La pila de protocolos de Internet sigue evolucionando mediante el mecanismo conocido como RFC("Request For Comments". Los investigadores están diseñando e implementando nuevos protocolos(en su mayoría del nivel de aplicación), que se ponen en conocimiento de la comunidad de Internet en la forma de un RFC. (0)El RFC es descrito por el IAB("Internet Architecture Board". La mayor fuente de RFCs es el IETF("Internet Engineering Task Force" que es una organización subsidiaria del IAB. Sin embargo, cualquiera puede enviar un informe propuesto como RFC al editor de los RFC. Hay una serie de normas que los autores de RFCs deben seguir para que su RFC sea aceptado. Estas reglas se describen en un RFC(RFC 1543) que además indica como enviar una propuesta de RFC. Una vez que un RFC ha sido publicado, todas las revisiones y sustituciones se publican como nuevos RFCs. Se dice que un nuevo RFC que revisa o sustituye un RFC ya existente "actualiza" o "desfasa" a ese RFC. Asimismo, el RFC original es "actualizado" o "desfasado" por el nuevo. Por ejemplo, el RFC 1521 que describe el protocolo MIME es una "segunda edición", siendo una revisión del RFC 1341, y el RFC 1590 es una enmienda del 1521. Por tanto el RFC 1521 se etiqueta del modo siguiente: "Deja obsoleto al RFC 1341; Actualizado por el RFC 1590". En consecuencia, nunca hay confusión sobre si dos personas se refieren a dos versiones distintas de un RFC, Algunos RFCs se califican como documentos informativos mientras que otros describen protocolos de Internet. El IAB("Internet Architecture Board" mantiene una lista de todos los RFCs que describen la pila de protocolos. A cada uno de ellos se le asigna un estado y un status. Todo protocolo Internet puede tener uno de los siguientes estados: Estándar El IAB lo ha establecido como protocolo oficial de Internet. Se dividen en dos grupos: 1. El protocolo y superiores, protocolos que se aplican a la totalidad de Internet. 2. Protocolos específicos de redes, generalmente especificaciones del funcionamiento de IP en tipos concretos de redes. Estándar provisional El IAB está considerando activamente este protocolo como un posible protocolo estándar. Es deseable disponer de comentarios y pruebas exhaustivas cuantitativa y cualitativamente. Los comentarios y los resultados de las pruebas deberían enviarse al IAB. Existe la posibilidad de que se efectúen cambios en un protocolo estándar antes de que se convierta en estándar. Propuesto como estándar. Se trata propuestas de protocolos que el IAB puede considerar para la estandarización en el futuro. Es deseable evaluar la implementación y el testeo sobre un gran número grupos. Es probable que el protocolo se someta a revisión. Experimental Un sistema no debería implementar un protocolo experimental a menos que participe en el experimento y haya coordinado el uso que va a hacer del protocolo con el que lo ha desarrollado. Informativo Los protocolos desarrollados por otras organizaciones de estándares, o distribuidores, o aquellos que por otras razones son ajenos a los propósitos del IAB, pueden ser publicados a conveniencia de la comunidad de Internet como protocolos informativos. En algunos casos el IAB puede recomendar el uso de estos protocolos en Internet. Histórico Son protocolos con pocas posibilidades de convertirse alguna vez en estándar en Internet, bien porque han quedado desfasados por protocolos posteriores o debido a la falta de interés. Definiciones de los status de los protocolos: Requerido Un sistema debe implementar los protocolos requeridos. Recomendado Un sistema debería implementar un protocolo recomendado. Electivo Un sistema puede o no implementar un protocolo electivo. La idea general es que si vas a implementarlo, debes hacerlo exactamente como se define. Uso limitado. Estos protocolos son usados en circunstancias específicas. Esto se puede deber a su estado experimental, naturaleza específica, funcionalidad limitada o estado histórico. No recomendado. Estos protocolos no se recomiendan para el uso general. Esto se puede deber a su limitada funcionalidad, naturaleza específica, o a que su estado es experimental o histórico. 1.5.1 Estándares de Internet Los estándares propuestos, provisionales, y los protocolos estándar figuran en el "Internet Standards Track"("Seguimiento de estándares de Internet". El seguimiento de estándares es controlado por el IESG("Internet Engineering Steering Group" del IETF. Cuando un protocolo alcanza el estado de estándar, se le asigna un número de estándar(STD). El propósito del STD es indicar claramente que RFCs describen estándares de Internet. Los números STD referencian múltiples RFCs cuando la especificación de un estándar está repartida entre varios documentos. A diferencia de los RFCs, donde el número se refiere a un documento específico, los números STD no cambian cuando un estándar es actualizado. Sin embargo, los STD carecen de número de versión ya que todas las actualizaciones se hacen a través de RFCs y los RFCs son únicos. De este modo, para especificar sin ambigüedades a que estándar se refiere uno, el número de estándar y todos los RFCs que incluye deberían ser mencionados. Por ejemplo, el DNS("Domain Name System" tiene el STD 13, y se describe en los RFCs 134 y 1035. Para referenciar un estándar, se debería usar una forma como "STD-13/RFC-1034/RFC-1035". Para una descripción de los procedimientos para estándares, remitirse al RFC 1602 -- Los procedimientos para estándares de Internet - Revisión 2. Para el seguimiento de algunos estándares, el status del RFC no siempre contiene suficiente información como para ser útil. Por ello se le añade un descriptor de aplicabilidad, dado bien en la forma de STD 1 en un RFC separado; este descriptor lo dan particularmente los protocolos de encaminamiento. En este documento se hacen referencias a RFCs y número STD, ya que constituyen la base de todas las implementaciones de protocolos TCP/IP. Cuatro estándares de Internet son de particular importancia: STD 1 - Estándares de protocolo oficiales en Internet Este estándar da el estado y el status de cada estándar o protocolo de Internet, y define los significados atribuidos a cada estado o status. El IAB suele emitirlo aproximadamente cada trimestre. En el momento de escribir este documento, este estándar va por el RFC 1780 (marzo de 1995). STD 2 - Números asignados de Internet Este estándar lista los número asignados actualmente y otros parámetros de protocolos en la pila de protocolos de Internet. Es emitido por IANA("Internet Assigned Numbers Authority". La edición actual en el momento de escribir este documento se corresponde con el RFC 1700 (octubre de 1994). STD 3 - Requerimientos de host Este estándar define los requerimientos para el software de Internet del host (con frecuencia a través de referencias a RFCs importantes). El estándar aparece dividido en dos partes: el RFC 1122 - Requerimientos para hosts en Internet - de la capa de comunicaciones y el RFC 1123 - Requerimientos para hosts en Internet - de aplicación y soporte. STD 4 - Requerimientos de pasarela Este estándar define los requerimientos para el software de pasarelas. Su RFC es el 1009. 1.5.2 Para Su Información("For Your Information(FYI)" Cierto número de RFCs que tienen un amplio interés para los usuarios de Internet se clasifican como documentos FYI("For Your Information". Frecuentemente contienen información de ayuda o de carácter introductorio. Como los números STD, un FYI no se cambia cuando se publica un RFC revisado. A diferencia de los STDs, los FYIs corresponden a un único RFC. Por ejemplo, el FYI 4 -- FYI acerca de preguntas y respuestas - Respuesta a preguntas habituales de nuevos usuarios de Internet va en la actualidad por su cuarta edición. Los números de RFC son 1177, 1206, 1325 y 1594. 1.5.3 Obteniendo RFCs Todos los RFCs están disponibles para el público, en forma de documento tanto impreso como electrónico, por medio del Internic("Internet Network Information Center"; internic.net). Antes de 1993, el DNN NIC(nic.ddn.mil) realizaba la función del NIC. Consultar el RFC 1400 para tener más información acerca de esta transición. * Los RFCs pueden conseguirse en forma impresa de: Network Solutions, Inc. Attn: InterNIC Registration Service 505 Huntmar Park Drive Herndon, VA 22070 Help Desk Telephone Number: 703-742-4777 FAX Number 703-742-4811 * Para conseguir el documento electrónico, los usuarios pueden hacer un FTP anónimo a ds.internic.net (198.49.45.10) y tomar los ficheros del directorio rfc, o un Gopher a internic.net (198.41.0.5). * Para información sobre otros métodos de acceder a RFCs vía E-mail o FTP, envía un E-mail a "rfc-info@ISI.EDU" con el mensaje "help: ways_to_get_rfcs". Por ejemplo: To: rfc-info@ISI.EDU Subject: getting rfcs help: ways_to_get_rfcs * * Si tienes acceso a Internet, hay muchos sitios que mantienen archivos de RFCs. Uno que podrías probar es el "MAGIC Document Archive" en http://www.msci.magic.net/docs/rfc/rfc_by_num.html. Los RFCs también se pueden obtener a través de la red IBM VNET usando el siguiente comando: EXEC TOOLS SENDTO ALMVMA ARCNET RFC GET RFCnnnn TXT * Donde nnnn es el número del RFC. Para conseguir una lista de todos los RFCs(y saber si están disponibles en formato TXT o postscript), usa el comando: EXEC TOOLS SENDTO ALMVMA ARCNET RFC GET RFCINDEX TXT * También están los archivos STDINDEX TXT y FYIINDEX TXT que listan aquellos RFCs que tienen un número ST o FYI. 1.5.4 Principales protocolos de Internet Para dar una idea de la importancia de los principales protocolos, listamos algunos de ellos junto con su estado actual, status y STD donde es aplicable en Tabla - Estado, status y números STD actuales de protocolos importantes de Internet. La lista completa se puede encontrar en RFC 1780 - Estándares de protocolos oficiales en Internet. Leyenda: Estado: Std. = Estándar; Draft = Estándar provisional; Prop. = Propuesto como estándar; Info. = Informativo; Hist. = Histórico Status: Req. = Requerido; Rec. = Recomendado; Ele. = Electivo; Not = No Recomendado Tabla: Estado, status y números STD actuales de protocolos importantes de Internet En el momento de escribir este documento, no hay ningún RFC asociado al protocolo de transferencia de hipertexto("HTTP" usado en implementaciones de la "World Wide Web". Sin embargo, el documento HyperText Transfer Protocol (HTTP) escrito por Tim Berners-Lee se puede obtener en ftp://info.cern.ch/pub/www/doc/http-spec.text. Adicionalmente, los siguientes RFCs describen el URL("Uniform Resource Locator" y conceptos asociados a él: * RFC 1630 - Identificadores universales de recursos en WWW * RFC 1737 - Requerimientos funcionales para los URN("Uniform Resource Names" * RFC 1738 - URL("Uniform Resource Locators" Proximamente 2 parte
2.3 IP("Internet Protocol" Figura: IP("Internet Protocol" IP es un protocolo estándar con STD 5 que además incluye ICMP (ver ICMP("Internet Control Message Protocol") e IGMP (ver IGMP("Internet Group Management Protocol"). Su status es requerido. Su especificación actual se puede encontrar en los RFCs 791, 950, 919 y 922, que actualizado en el RFC 1349. IP es el protocolo que oculta la red física subyacente creando una vista de red virtual. Es un protocolo de entrega de paquetes no fiable y no orientado a conexión, y se puede decir que aplica la ley del mínimo esfuerzo. No aporta fiabilidad, contrtol de flujo o recuperación de errores a los prots de red inferiores. Los paquetes (datagramas) que envía IP se pueden perder, desordenarse, o incluso duplicarse, e IP no manejará estas situaciones. El proporcionar estos servicios depende de prots superiores. IP asume pocas cosas de las capas inferiores, sólo que los datagramas "probablemente" serán transportados al host de destino. 2.3.1 El datagrama IP El datagrama IP es la unidad de transferencia en la pila IP. Tiene una cabecera con información para IP, y los datos relevantes para los prots superiores. Figura: El datagrama IP El datagrama IP está encapsulado en la trama de redd subyacente, que suele tener una longitud máxima, dependiendo del hardware usado. Para Ethernet, será típicamente de 1500 bytes. En vez de limitar el datagrama a un tamaño máximo, IP puede tratar la fragmentación y el re-ensamblado de sus datagramas. En particular, el IP est no impone una tamaño máximo, pero establece que todas las redes deberían ser capaces de manejar al menos 576 bytes. Los fragmentos de datagramas tienen todos una cabecera, copiada básicamente del datagrama original, y de los datos que la siguen. Se tratan como datagramas normales mientras son transportados a su destino. Nótese, sin embargo, que si uno de los fragmentos se pierde, todo el datagrama se considerará perdido, y los restantes fragmentos se considerarán perdidos. 2.3.1.1 Formato del datagrama IP La cabecera del datagrama IP es de un mínimo de 20 bytes de longitud: igura: Formato del datagrama IP Donde: VERS La versión del protocolo IP. La versión actual es la 4. La 5 es experimental y la 6 es IPng(ver IP: La próxima generación(IPng)). LEN La longitud de la cabecera IP contada en cantidades de 32 bits. Esto no incluye el campo de datos. Type of Service El tipo de servicio es una indicación de la calidad del servicio solicitado para este datagrama IP. Donde: Precedencia Es una medida de la naturaleza y prioridad de este datagrama: 000 Rutina 001 Prioridad 010 Imediato 011 "Flash" 100 "Flash override" 101 Crítico 110 Control de red("Internetwork control" 111 Control de red("Network control" TOS TOS("type of service": 1000 Minimizar retardo 0100 Maximizar la densidad de flujo 0010 Maximizar la fiabilidad 0001 Minimizar el coste monetario 0000 Servicio normal MBZ Reservado para uso futuro(debe ser cero, a menos que participe en un experimento con IP que haga uso de este bit) Una descripción detallada del TOS se puede encontrar en el RFC 1349. Total Length La longitud total del datagrama, cabecera y datos, especificada en bytes. Identification Un número único que asigna el emisor para ayudar a reensamblar un datagrama fragmentado. Los fragmentos de un datagrama tendrán el mismo número de identificación. Flags Varios flags de control: Donde: 0 Reservado, debe ser cero DF No fragmentar("Don't Fragment": con 0 se permite la fragmentación, con 1 no. MF Más fragmentos("More fragments": 0 significa que se trata del último fragmento del datagrama, 1 que no es el último. Fragment Offset Usado con datagramas fragmentados, para ayudar al reensamblado de todo el datagrama. El valor es el número de partes de 64 bits(no se cuentan los bytes de la cabecera) contenidas en fragmentos anteriores. En el primer(o único) fragmento el valor es siempre cero. Time to Live Especifica el tiempo(en segundos) que se le permite viajar a este datagrama. Cada "router" por el que pase este datagrama ha de sustraer de este campo el tiempo tardado en procesarlo. En la realidad un "router" es capaz de procesar un datagrama en menos de 1 segundo; por ello restará uno de este campo y el TTL se convierte más en una cuenta de saltos que en una métrica del tiempo. Cuando el valor alcanza cero, se asume que este datagrama ha estado viajando en un bucle y se desecha. El valor inicial lo debería fijar el protocolo de alto nivel que crea el datagrama. Protocol Number spotipprotn Indica el protocolo de alto nivel al que IP debería entregar los datos del datagrama. Algunos valores importantes son: 0 Reservado 1 ICMP("Internet Control Message Protocol" 2 IGMP ("Internet Group Management Protocol" 3 GGP("Gateway-to-Gateway Protocol" 4 IP (IP encapsulation) 5 Flujo("Stream" 6 TCP("Transmission Control" 8 EGP("Exterior Gateway Protocol" 9 PIRP("Private Interior Routing Protocol" 17 UDP ("User Datagram" 89 OSPF("Open Shortest Path First" La lista completa se puede encontrar en el STD 2 - Números asignados de Internet. Header Checksum Es el checksum de la cabecera. Se calcula como el complemento a uno de la suma de los complementos a uno de todas las palabras de 16 bits de la cabecera. Con el fin de este cálculo, el campo checksum se supone cero. Si el checksum dde la cabecera no se corresponde con los contenidos, el datagrama se desecha, ya que al menos un bit de la cabecera está corrupto, y el ddatagrama podría haber llegado al destino equivocado. Source IP Address La dirección IP de 32 bits del host emisor. Destination IP Address La dirección IP de 32 bits del host receptor. Options Longitud variable. No requiere que toda implementación de IP sea capaz de generar opciones en los datagramas que crea, pero sí que sea capaz de procesar datagramas que contengan opciones. El campo "Options" (opciones) tiene longitud variable. Puede haber cero o más opciones. Hay dos formatos para estas. El formato usado depende del valor del número de opción hallado en el primer byte. o Un byte de tipo("type byte" sólo. Un byte de tipo, un byte de longitud y uno o más bytes de opciones. El byte de tipo tiene la misma estructura en ambos casos: Donde: fc "Flag copy", que indica si el campo de opcions se ha de copiar(1) o no(0) cuando el datagrama está fragmentado. class Un entero sin signo de 2 bits: 0 control 1 reservado 2 depurado y mediciones 3 reservado option number Entero sin signo de 5 bits. 0 Fin de la lista de opciones, con "class" a cero, fc a cero, y sin byte de longitud o de datos. Es decir, la lista termina con el byte X'00'. Sólo se requiere si la longitud de la cabecera IP(que es un múltiplo de 4 bytes) no se corresponde con la longitud real de las opciones. 1 No operación. Tiene "class" a cero, fc a cero y no hay byte de longitud ni de ddatagramaos. Es decir, un byte X'01' es NOP("no operation". Se puede usar para alinear campos en el datagrama. 2 Securidad. Tiene "class" a cero, fc a uno y el byte de longitud a 11 y el de datos a 8. Se usa para la información de seguridad que necesitan las especificaciones del departamento de defensa de los US. 3 LSR("Loose Source Routing". Tiene "class" a cero, fc a uno y hay un campo de datos de longitud variable. 4 IT("Internet Timestamp". Tiene "class" a 2, fc a cero y hay un campo de datos de longitud variable. 7 RR("Record Route". Tiene "class" a 0, fc a cero y hay un campo de datos de longitud variable. 8 SID("Stream ID", o identificador de flujo). Tiene "class" a 0, fc a uno y hay un byte de longitud a 4 y un byte de datos. Se usa con el sistema SATNET. 9 SSS("Strict Source Routing". Tiene "class" a 0, fc a uno y hay un campo de datos de longitud variable. length cuenta la longitud(en bytes) de la opción, incluyendo los campo de tipo y longitud. option data no contiene datos relevantes para la opción. padding Si se usa una opción, el datagrama se rellena con bytes a cero hasta la siguiente palabra de 32 bits. data Los datos contenidos en el datagrama se pasan a un protocolo de nivel superior, como se especifica en el campo protocol. 2.3.1.2 Fragmentación Cuando un datagrama IP viaja de un host a otro puede cruzar distintas redes físicas. Las redes físicas imponen un tamaño máximo de trama, llamado MTU("Maximum Transmission Unit", que limita la longitud de un datagrama. Por ello, existe un mecanismo para fragmentar los datagramas IP grandes en otros más pequeños, y luego reensamblarlos en el host de destino. IP requere que cada enlace tenga un MTU de al menos 68 bytes, de forma que si cualquier red proporciona un valor inferior, la fragmentación y el rensamblado tendrán que implementarse en la capa de la interfaz de red de forma transparente a IP. 68 es la suma de la mayor cabecera IP, de 60 bytes, y del tamaño mínimo posible de los datos en un fragmento(8 bytes). Las implementaciones de IP no están obligadas a manejar datagrama sin fragmentar mayores de 576 bytes, pero la mayoría podrá manipular valores más grandes, típicamente ligeramente más de 8192 bytes, o incluso mayores, y raramente menos de 1500. Un datagrama sin fragmentar tiene a cero toda la información de fragmentación. Es decir, el flag fc y el fo(fragment offset) están a cero. Cuando se ha de realizar la fragmentación, se ejecutan los siguientes pasos: * Se chequea el bit de flag DF para ver si se permite fragmentación. Si está a uno, el datagrama se desecha y se devuelve un error al emisor usando ICMP. * Basándose en el valor MTU, el campo de datos se divide en dos o más partes. Todas las nuevas porciones de datos, excepto la última, se alinean a 8 bytes. * Todas las porciones de datos se colocan en datagramas IP. Las cabeceras se copian de la cabecera original, con algunas modificaciones: o El bit de flag mf(more fragments) se pone a uno en todos los fragmentos, excepto en el último. o El campo fo se pone al valor de la localización de la porción de datos correspondiente en el at original, con respecto al comienzo del mismo. Su valor se mide en unidades de 8 bytes. o Si se incluyeron opciones en el datagrama original, el bit de orden superior del byte "type option" determina si se copiaran o no en todos los fragmentos o sólo en el primero. Por ejemplo, las opciones e encaminamiento de la fuente se tendrán que copiar en todos los fragmentos y por tanto tendrán a uno este bit. o Se inicializa el campo de longitud(length) del nuevo datagrama. o Se inicializa el campo de longitud(length) total del nuevo datagrama. o Se recalcula el checksum de la cabecera. * Cada uno de estos datagramas se envía como un datagrama IP normal. IP maneja cada fragmento dde forma independiente, es decir, los fragmento pueden atravesar diversas rutas hacia su destino, y pueden estar sujetos a nuevas fragmentaciones si pasan por redes con MTUs inferiores. En el host de destino, los datos se tienen que reensamblar. El host emisor inicializó el campo ID a un número único(dentro de los límites impuestos por el uso de un número de 16 bits). Como la fragmentación no altera este campo, los fragmentos que le van llegando al destino se pueden identificar, si este ID se usa junto con las direcciones IP fuente y destino(source, destination) del datagrama. También se chequea el campo de protocolo Con el fin de reensamblar los fragmentos, el receptor destina un buffer de almacenamiento en cuanto llega el primer fragmento. Se inicia una rutina para un contador. Cuando el contador a un timeout y no se han recibido todos los datagramas, se desecha el datagrama. El valor inicial el contador es el TTL(time-to-live). Depende de la implementación, y algunas permiten configurarlo. Cuando llegan los fragmentos siguientes, antes de que expire el tiempo, los datagramas se copian al buffer en la localización indicada por el fo(fragment offset). Cuando han llegado todos los datagramas, se restaura el datagrama original y continúa su procesamiento. Nota: IP no proporciona el contador de reensamblado. Tratará cada datagrama, fragmentado o no, de la misma forma. Depende de una capa superior el implementar un timeout y reconocer la pérdida de fragmentos. Esta capa podría ser TCP para el transporte en un red orientada a conexión o UDP, para el caso contrario. 2.3.1.3 Opciones de encaminamiento del datagrama IP El campo "options" del datagrama IP admite dos métodos para que el generador del datagrama dé explícitamente información de encaminamiento y uno para que el datagrama determine a ruta que va a emplear. LSR("Loose Source Routing" Esta opción, conocida también como LSRR("Loose Source and Record Route", proporciona un medio para que la fuente del dar suministre información de encaminamiento explícita que usarán los "routers" que retransmitan el datagrama, y para grabar la ruta seguida. Figura: Opción LSR 1000011 (131 decimal) es el valor del byte "option" para LSR. length contiene la longitud de este campo, incluyendo los campos "type" y "length". pointer apunta a los datagramas de la opción en la siguiente dirección IP a procesar. Es relativo al comienzo de la opción, por lo que su valor mínimo es de cuatro. Si su valor supera la longitud de la opción, se alcanza el final de la ruta de la fuente y el resto del encaminamiento se ha de basar en la dirección IP de destino(como en los datagramas que no tienen esta opción). route data es una serie de direcciones IP de 32 bits. Siempre que un datagrama llega a su destino y la ruta de la fuente no está vacía(pointer < length) el receptor: * Tomará la siguiente dirección IP de este campo(el indicado por "pointer" y lo pondrá en el campo de la dirección IP de destino el datagrama. * Pondrá la dirección IP local en la SL(source list) en la localización a la que apunte "pointer". La dirección IP local es la correspondiente a la red por la que se enviará el datagrama. * Incrementará "pointer" en 4. * Transmitirá el datagrama a la nueva dirección IP de destino. Este procedimiento asegura que la ruta de retorno se graba en "route datagram"(en orden inverso) de modo que el receptor use estos datagramas para construir un LSR en el sentido inverso. Se denomina LSR("loose source route" porque al "router" retransmisor se le permite usar cualquier ruta y cualquier número de host intermedios para alcanzar la siguiente dirección de la ruta. Nota: El host emisor pone la dirección IP del primer "router" intermedio en el campo dirección IP de destino y las direcciones de los demás "routers" de la ruta, incluyendo el destino, en la opción "source route". La ruta que hay grabada en el datagrama cuando este llega al objetivo contiene las direcciones IP de cada uno de los "routers" que retransmitió el datagrama. SSR("Strict Source Routing" Esta opción, llamada también SSRR(Strict Source and Record Route", emplea el mismo principio que LSR exceptuando que el "router" intermedio debe enviar el datagrama a la siguiente dirección IP en la ruta especificada por la fuente a través de una red conectada directamente y no por medio de un "router" intermedio. Si no puede hacerlo, envía un mensaje ICMP "Destination Unreachable". Figura: Opción SSR 1001001 (137 decimal) es el valor del byte "option" para el método SSR length tiene el mismo significado que para LSR pointer tiene el mismo significado que para LSR route data es una serie de direcciones IP RR(Record Route) Esta opción proporciona un medio para grabar la ruta de un datagrama IP. Funciona de modo similar al SSR anterior, pero en este caso el host fuente deja el campo de datos de encaminamiento vacío, que se irá llenando a medida que el datagrama viaja. Nótese que el host fuente debe dejar suficiente espacio para esta información: si el campo se llena antes de que el datagrama llegue a su destino, el datagrama se retransmitirá, pero se dejará de grabar la ruta. Figura: Opción RR 0000111 (7 decimal) es el valor del byte "option" para el método RR length tiene el mismo significado que para LSR pointer tiene el mismo significado que para LSR route data su longitud es un múltiplo de cuatro bytes, y lo elige el generador del datagrama 2.3.1.4 IT(Internet Timestamp) El "timestamp " o sello de tiempo es una opción para forzar a algunos(o a todos) de los "routers" de la ruta hacia el destino a poner un "timestamp" en los datos de la opción. Los "timestamps" se miden en segundos y se pueden usar para la depuración. No se pueden emplear para medir el rendimiento por dos razones: * No son lo bastante precisos porque la mayoría de los datagramas se envían en menos de un segundo. * No son lo bastante precisos porque los "router" no han de tener relojes sincronizados. Figura: Opción IT Donde 01000100 (68 decimal) es el valor del byte "option" para IT. length Contiene la longitud total de esta opción, incluyendo los campos "type" y "length". pointer Apunta al siguiente "timestamp" a procesar(el primero que esté disponible). oflw (overflow) Es un entero sin signo de 4 bits que indica el número de módulos IP que no pueden registrar "timestamps" por falta de espacio en el campo de datos. flag Es una valor de 4 bits que indica cómo se han de registrar los "timestamps". Los valores posibles son: 0 Sólo "timestamps", almacenados en palabras consecutivas de 32 bits. 1 Cada "timestamp" se precede con la dirección IP del módulo que efectúa el registro. 2 La dirección IP se pre-especifica, y un módulo IP sólo realiza el registro cuando encuentra su propia dirección en la lista. timestamp Un "timestamp" de 32 bits medido en milisegundos desde la medianoche según UT (GMT). El host emisor debe componer esta opción con un área de datos los bastante grande para almacenar todos los "timestamps". Si el área de los "timestamps" se llena, no se añaden más. 2.3.2 Encaminamiento IP Una función importante de la capa IP es el encaminamiento. Proporciona los mecanismos básicos para interconectar distintas redes físicas. Esto significa que un host puede actuar simultáneamente como host normal y como "router". Un "router" básico de este tipo se conoce como "router" con información parcial de encaminamiento, ya que sólo contiene información acerca de cuatro tipos de destino: * Los hosts conectados directamente a una de las redes físicas a las que está conectado el "router" * Los host o redes para las se le han dado al "router" definiciones específicas * Los hosts o redes para las que el host ha recibido un mensaje ICMP redirect * Un destino por defecto para todo lo demás Los dos últimos casos permiten a un "router" básico comenzar con una cantidad muy limitada de información para irla aumentando debido a que un "router" más avanzado lance un mensaje ICMP redirect cuando reciba un datagrama y conozca un "router" mejor en la misma red al que dirigir el datagrama. Este proceso se repite cada vez que un "router" básico se reinicia. Se necesitan protocolo adicionales para implementar un "router" completamente funcional que pueda intercambiar información con otros "routers" en redes remotas. Tales "routers" son esenciales, excepto en redes pequeñas, y los protocolos que usan se discuten en Protocolos de encaminamiento. 2.3.2.1 Destinos directos e indirectos Si el host de destino está conectado a una red a la que también está conectado el host fuente, un datagrama IP puede ser enviado directamente, simplemente encapsulando el datagrama IP en un trama. Es lo que se llama encaminamiento directo. El encaminamiento indirecto ocurre cuando el host de destino no está en una red conectada directamente al host fuente. La única forma de alcanzar el destino es a través de uno o más "routers". La dirección del primero de ellos(el primer salto) se llama ruta indirecta. La dirección del primer salto es la única información que necesita el host el "router" que reciba el datagrama se responsabiliza del segundo salto, y así sucesivamente. Figura: Rutas IP directas e indirectas - El host A tiene una ruta directa con B y D, y una indirecta con C. El host D es un "router" entre las redes 129.1 y 129.2. Un host puede distinguir si una ruta es directa o indirecta examinando el número de red y de subred de la dirección IP. 1. Si coinciden con una de las direcciones IP del host fuente, la ruta es directa. El host necesita ser capaz de direccionar correctamente el objetivo usando un protocolo inferior a IP. Esto se puede hacer automáticamente, usando un protocolo como ARP(ver ARP("Address Resolution Protocol"), que se usan en LANs con broadcast, o estáticamente y configurando el host, por ejemplo cuando un host MVS tiene una conexión TCP/IP sobre un enlace SNA. 2. Para rutas indirectas, el único conocimiento requerido es la dirección IP de un "router" que conduzca a la red de destino. Las implementaciones de IP pueden soportar también rutas explícitas, es decir, una ruta a una dirección IP concreta. Esto es habitual en las conexiones que usan SLIP("Serial Line Internet Protocol" que no proporciona un mecanismo para que dos hosts se informen mutuamente de sus direcciones IP. Tales rutas pueden tener incluso el mismo número de red que el host, por ejemplo en subredes compuestas de enlaces punto a punto. En general, sin embargo, la información de encaminamiento se genera sólo mediante los números de red y de subred. 2.3.2.2 Tabla de encaminamiento IP Cada host guarda el conjunto de mapeados entre las direcciones IP de destino y las direcciones IP del siguiente salto para ese destino en una tabla llamada tabla de encaminamiento IP. En esta tabla se pueden encontrar tres tipos de mapeado: 1. Rutas directas, para redes conectadas localmente 2. Rutas indirectas, para redes accesibles a través de uno o más "routers" 3. Un ruta por defecto, que contiene la ir IP de un "router" que todas las direcciones IP no contempladas en las rutas directas e indirectas han de usar. Ver la red en Figura - Ejemplo de tabla de encaminamiento IP para un ejemplo. Figura: Ejemplo de tabla de encaminamiento IP La tabla de encaminamiento contiene las siguientes entradas Destination route via 128.10 direct attachment 128.15 direct attachment 129.7 128.15.1.2 default 128.10.1.1 2.3.2.3 Algoritmo de encaminamiento IP De los principios ya comentados de IP, es fácil deducir los pasos que IP debe tomar con el fin de determinar la ruta para un datagrama de salida. Es lo que se denomina algoritmo de encaminamiento IP, y se muestra esquemáticamente en Figura - Algoritmo de encaminamiento IP. igura: Algoritmo de encaminamiento IP Nótese que se trata de un proceso iterativo. Se aplica a todo host que maneje un datagrama, exceptuando al host al que se entrega finalmente el datagrama. 2.4 ICMP("Internet Control Message Protocol" Figura: ICMP("Internet Control Message Protocol" ICMP es un protocolo estándar con número STD 5, que además incluye IP(ver IP("Internet Protocol") e IGMP (ver IGMP("Internet Group Management"). Su status es requerido. Se describe en el RFC 792, actualizado en el RFC 950. "Path MTU Discovery" es un protocolo estándar provisional con status electivo. Se describe en el RFC 1191. ICMP "Router Discovery" es un protocolo propuesto como estándar con status electivo. Es descrito en el RFC 1256. Cuando un "router" o un host de destino debe informar al host fuente acerca del procesamiento de datagramas, utiliza el ICMP("Internet Control Message Protocol". ICMP puede caracterizarse del modo siguiente: * ICMP usa IP como si ICMP fuera un protocolo del nivel superior(es decir, los mensajes ICMP se encapsulan en datagramas IP). Sin embargo, ICMP es parte integral de IP y debe ser implementado por todo módulo IP. * ICMP se usa para informar de algunos errores, no para hacer IP fiable. Aún puede ocurrir que los datagramas no se entreguen y que no se informe de su pérdida. La fiabilidad debe ser implementada por los protocolos de nivel superior que usan IP. * ICMP puede informar de errores en cualquier datagrama IP con la excepción de mensajes IP, para evitar repeticiones infinitas. * Para datagramas IP fragmentados, los mensajes ICMP sólo se envían para errores ocurridos en el fragmento cero. Es decir, los mensajes ICMP nunca se refieren a un datagrama IP con un campo de desplazamiento de fragmento. * Los mensajes ICMP nunca se envían en respuesta a datagramas con una dirección IP de destino que sea de broadcast o de multicast. * Los mensajes ICMP nunca se envían en respuesta a un datagrama que no tenga una dirección IP de origen que represente a un único host. Es decir, la dirección de origen no puede ser cero, una dirección de looopback, de broadcast o de multicast. * Los mensajes ICMP nunca se envían en respuesta a mensajes ICMP de error. Pueden enviarse en respuesta a mensajes ICMP de consulta(los tipos de mensaje ICMP 0, 8, 9, 10 y 13 al 18). * El RFC 792 establece que los mensajes ICMP "pueden" ser generados para informar de errores producidos en el procesamiento de datagramas IP, no que "deban". En la práctica, los "routers" generarán casi siempre mensajes ICMP para los errores, pero en el caso de los host de destino, el número de mensajes ICMP generados es una cuestión de implementación. 2.4.1 Mensajes ICMP Los mensajes ICMP se describen en los RFCs 792 y 950, correspondientes al STD 5 y son obligatorios. Los mensajes ICMP se envían en datagramas IP. La cabecera IP siempre tendrá un número de protocolo de 1, indicando que se trata de ICMP y un servicio de tipo 0(rutina). El campo de datos de IP contendrá el auténtico mensaje ICMP en el formato mostrado en Figura - Formato de mensajes ICMP. Figura: Formato de mensajes ICMP Donde: Type Especifica el tipo del mensaje: 0 Echo reply 3 Destination unreachable 4 Source quench 5 Redirect 8 Echo 9 Router Advertisement 10 Router Solicitation 11 Time exceeded 12 Parameter Problem 13 Timestamp request 14 Timestamp reply 15 Information request(obsolete) 16 Information reply(obsolete) 17 Adress mask request 18 Adress mask reply Code Contiene el código de error para el datagrama del que da parte el mensaje ICMP. La interpretación depende del tipo de mensaje. Checksum Contiene el complemento a 1 de 16 bits de la suma del "ICMP message starting with the ICMP Type field". Para computar este checksum se asume en principio que su valor es cero. Este algoritmo es el mismo que el usado por IP para el cálculo de la cabecera IP. Compárese con el algoritmo de UDP y TCP(ver UDP("User Datagram Protocol" y TCP("Transmission Control Protocol") que incluyen además una pseudocabecera-IP en el checksum. Data Contiene información para el mensaje ICMP. Típicamente se tratará de parte del mensaje IP original para el que se generó el mensaje ICMP. La longitud de los datos puede calcularse como la diferencia entre la longitud del datagrama IP que contiene el mensaje y la cabecera IP. Cada uno de los mensajes se explica abajo. 2.4.1.1 Echo Reply (0) Ver Echo (8) y Echo Reply (0). 2.4.1.2 Destination Unreachable (3) Figure: destination unreachable o " destino inalcanzable" de ICMP Si este mensaje es recibido de un "router" intermediario, significa que el "router" considera la dirección IP de destino como inalcanzable. Si se recibe este mensaje del host de destino, significa que el protocolo especificado en el campo de número de protocolo del datagrama original no está activo, que ese protocolo no está activo en ese host o bien que es el puerto indicado el que no está activo(ver UDP("User Datagram Protocol" para una introducción al concepto de puerto). El campo de código de cabecera tendrá uno de los siguientes valores: 0 network unreachable 1 host unreachable 2 protocol unreachable 3 port unreachable 4 fragmentation needed but the Do Not Fragment bit was set 5 source route failed 6 destination network unknown 7 destination host unknown 8 source host isolated (obsolete) 9 destination network administratively prohibited 10 destination host administratively prohibited 11 network unreachable for this type of service 12 host unreachable for this type of service 13 communication administratively prohibited by filtering 14 host precedence violation 15 precedence cutoff in effect Si un "router" implementa el protocolo de resolución de caminos MTU, el formato del mensaje "Destination unreachable" se cambia por el código 4 para incluir el MTU del enlace que no pudo aceptar el datagrama. Pronto parte 5

Capítulo 2. Arquitectura y protocolos En este capítulo comenzaremos con una introducción a TCP/IP y describiendo sus propiedades básicas, tales como la formación de redes, la distribución de protocolos por capas y el encaminamiento. A continuación discutiremos cada uno de los protocolos específicos en detalle. 2.1 Modelo arquitectónico La pila TCP/IP se llama así por dos de sus protocolos más importantes: : TCP("Transmission Control Protocol" de IP("Internet Protocol". Otro nombre es pila de protocolos de Internet, y es la frase oficial usada en documentos oficiales de estándares. En este manual utilizaremos el término TCP/IP, que es más habitual. 2.1.1 Redes La primera meta de diseño de TCP/IP fue construir una interconexión de redes que proporcionase servicios de comunicación universales: una red, o internet. Cada red física tiene su propia interfaz de comunicaciones dependiente de la tecnología que la implementa, en la forma de una interfaz de programación que proporciona funciones básicas de comunicación(primitivas). Las comunicaciones entre servicios las proporciona el software que se ejecuta entre la red física y la aplicación de usuario, y da a estas aplicaciones una interfaz común, independiente de la estructura de la red física subyacente. La arquitectura de las redes físicas es transparente al usuario. El segundo objetivo es interconectar distintas redes físicas para formar lo que al usuario le parece una única y gran red. Tal conjunto de redes interconectadas se denomina "internetwork" o internet. Para poder interconectar dos redes, necesitamos un ordenador que esté conectado a ambas redes y que pueda retransmitir paquetes de una a la otra; tal máquina es un "router". El término "router" IP también se usa porque la función de encaminamiento es parte de la capa IP de la pila TCP/IP(Ver protocolos por capas). Figura - Ejemplos muestra dos ejemplo de "internetworks". Figura: Ejemplos - Dos conjuntos interconectados de redes, cada uno visto como una red lógica. Las propiedades básicas de un "router" son: * Desde el punto de vista de la red, es un host normal. * Desde el punto de vista del usuario, es invisible. El usuario sólo ve una gran red. Para ser capaz de identificar un host en la red, a cada se le asigna una dirección, la dirección IP. Cuando un host tiene múltiples adaptadores de red, cada adaptador tiene una dirección IP separada. La dirección IP consta de dos partes: dirección IP = <número de red><número de host> El número de red lo asigna una autoridad central y es unívoco en Internet. La autoridad para asignar el número de host reside en la organización que controla la red identificada por el número de red. El esquema de direccionamiento se describe en detalle en Direccionamiento. 2.1.2 Arquitectura de Internet La pila TCP/IP ha evolucionado durante unos 25 años. Describiremos algunos de sus aspectos mas importantes en los siguientes capítulos. 2.1.2.1 Protocolos por capas TCP/IP, como la mayoría del software de red, está modelado en capas. Esta representación conduce al término pila de protocolos. Se puede usar para situar(pero no para comparar funcionalmente) TCP/IP con otras pilas, como SNA y OSI("Open System Interconnection". Las comparaciones funcionales no se pueden extraer con facilidad de estas estructuras, ya que hay diferencias básicas en los modelos de capas de cada una. Los protocolos de Internet se modelan en cuatro capas: Figura: Modelo arquitectónico - Cada capa representa un ":q.package:eq." de funciones. Aplicación es a un proceso de usuario que coopera con otro proceso en el mismo o en otro host. Ejemplos son TELNET (un protocolo para la conexión remota de terminales), FTP ("File Transfer Protocol" y SMTP ("Simple Mail Transfer Protocol". Estos se discuten con más detalle en protocolos de aplicación. Transporte proporciona la transferencia de datos de entre los extremos. Ejemplo son TCP(orientado a conexión) y UDP(no orientado a conexión). Ambos se discuten en detalle en TCP("Transmission Control Protocol" y UDP("User Datagram Protocol" "Internetwork" también llamada capa de red, proporciona la imagen de "red virtual" de Internet(es decir, oculta a los niveles superiores la arquitectura de la red). IP("Internet Protocol" es el protocolo más importante de esta capa. Es una protocolo no orientado a conexión que no asume la fiabilidad de las capas inferiores. No suministra fiabilidad, control de flujo o recuperación de errores. Estas funciones debe proporcionarlas una capa de mayor nivel, bien de transporte con TCP, o de aplicación, si se utiliza UDP como transporte. IP se discute con detalle en IP("Internet Protocol". Una unidad de un mensaje en una red IP se denomina datagrama IP. Es la unidad básica de información transmitida en redes TCP/IP networks. Se describe en El datagrama IP. Network Interface o capa de enlace o capa de enlace de datos, constituye la interfaz con el hardware de red. Esta interfaz puede proporcionar o no entrega fiable, y puede estar orientada a flujo o a paquetes. De hecho, TCP/IP no especifica ningún protocolo aquí, pero puede usar casi cualquier interfaz de red disponible, lo que ilustra la flexibilidad de la capa IP. Ejemplos son IEEE 802.2, X.25 (que es fiable por sí mismo), ATM, FDDI, PRN("Packet Radio Networks", como AlohaNet) de incluso SNA. Las interacciones reales se muestran con flechas en Figura - Modelo arquitectónico. Un modelo de capas más detallado se muestra en Figura - Modelo arquitectónico detallado. Figura: Modelo arquitectónico detallado 2.1.2.2 Puentes, "routers" y pasarelas La formación de una red conectando múltiples redes se consigue por medio de los "routers". Es importante distinguir entre un "router", un puente y una pasarela. Puente Interconecta segmentos de LAN a nivel de interfaz de red y envía tramas entre ellos. Un puente realiza la función de retransmisión MAC, y es independiente de cualquier capa superior (incluyendo el enlace lógico). Proporciona, si se necesita, conversión de protocolo a nivel MAC. Un puente es transparente para IP. Es decir, cuando un host envía un datagrama a otro host en una red con el que se conecta a través de un puente, envía el datagrama al host y el dar cruza el puente sin que el emisor se dé cuenta. "Router" Interconecta redes en el nivel de red y encamina paquetes entre ellas. Debe comprender la estructura de direccionamiento asociada con los protocolos que soporta y tomar la decisión de si se han de enviar, y cómo se ha de hacer, los paquetes. Los "routers" son capaces de elegir las mejores rutas de transmisión así como tamaños óptimos para los paquetes. La función básica de encaminamiento está implementada en la capa IP. Por lo tanto, cualquier estación de trabajo que ejecute TCP/IP se puede usar como "router". Un "router" es visible para IP. Es decir, cuando un host envía un dar IP a otro host en una red conectada por un "router", envía el datagrama al "router" y no directamente al host de destino. Pasarela Interconecta redes a niveles superiores que los puentes y los "routers". Una pasarela suele soportar el mapeado de direcciones de una red a otra, así como la transformación de datos entre distintos entornos para conseguir conectividad entre los extremos de la comunicación. Las pasarelas limitan típicamente la conectividad de dos redes a un subconjunto de los protocolos de aplicación soportados en cada una de ellas. Una pasarela es opaca para IP. Es decir, un host no puede enviar un datagrama IP a través de una pasarela: sólo puede enviarlo a la pasarela. La pasarela se ocupa de transmitirlo a la otra red con la información de los protocolos de alto nivel que vaya en él. Estrechamente ligado al concepto de pasarela, está el de cortafuegos("firewall" o pasarela cortafuegos, que se usa para restringir el acceso desde Internet a una red o un grupo de ellas, controladas por una organización, por motivos de seguridad. Ver Cortafuegos para más detalles. 2.1.2.3 Encaminamiento IP Los datagramas entrantes se chequean para ver si el host local es el destinatario: sí El datagrama se pasa a los protocolos de nivel superior. no El datagrama es para un host diferente. La acción depende del valor del flag "ipforwarding"(retransmisión IP). verdadero El datagrama se trata como si fuera un datagrama saliente y se encamina el siguiente salto según el algoritmo descrito abajo. falso El datagrama se desecha. En el protocolo de red, los datagramas salientes se someten al algoritmo de encaminamiento IP que determina dónde enviar el datagrama de acuerdo con la dirección de destino. * Si el host tiene una entrada en su tabla de encaminamiento IP (ver Encaminamiento IP básico) que concuerde con la ir de destino, el datagrama se envía a la dirección correspondiente a esa entrada. * Si el número de red de la dirección IP de destino es el mismo que el de uno de los adaptadores de red del host(están en la misma red) el datagrama se envía a la dirección física del host que tenga la dirección de destino. * En otro caso, el datagrama se envía a un "router" por defecto. Este algoritmo básico, necesario en toda implementación de IP, es suficiente para realizar las funciones de encaminamiento elementales. Como se señaló arriba, un host TCP/IP tiene una funcionalidad básica como "router", incluida en IP. Un "router" de esta clase es adecuado para encaminamiento simple, pero no para redes complejas. Los protocolos requeridos para redes complejas se describen en protocolos de encaminamiento. El mecanismo de encaminamiento IP, combinado con el modelo por capas de TCP/IP, se representa en Figura - El "router". Muestra un datagrama IP, yendo de una dirección IP(número de red X, host número A) a otra(número de red Y, host número B), a través de dos redes físicas. Nótese que en el "router" intermedio, sólo están implicados los niveles inferiores de la pila(red e interfaz de red). Figura: El "router" - La función de "router" la realiza el protocolo IP. 2.2 Direccionamiento Las direcciones de Internet pueden ser simbólicas o numéricas. La forma simbólica es más fácil de leer, por ejemplo: minombre@tcpip.com. La forma numérica es un número binario sin signo de 32 bits, habitualmente expresado en forma de números decimales separados por puntos. Por ejemplo, 9.167.5.8 es una dirección de Internet válida. La forma numérica es usada por el software de IP. La función de mapeo entre los dos la realiza el DNS(Domain Name System)discutido inDNS(Domain Name System). Primeramente examinaremos la forma numérica, denominada dirección IP. 2.2.1 La dirección IP Los estándares para las direcciones IP se describen en RFC 1166 -- Números de Internet. Para ser capaz de identificar una máquina en Internet, a cada interfaz de red de la máquina o host se le asigna una dirección, la dirección IP, o dirección de Internet. Cuando la máquina está conectada a más de una red se le denomina "multi-homed" y tendrá una dirección IP por cada interfaz de red. La dirección IP consiste en un par de números: IP dirección = <número de red<número de interfaz de red La parte de la dirección IP correspondiente al número de red está administrada centralmente por el InterNIC(Internet Network Information Center)y es única en toda la Internet.(1) Las direcciones IP son números de 32 bits representados habitualmente en formato decimal (la representación decimal de cuatro valores binarios de 8 bits concatenados por puntos). Por ejemplo128.2.7.9 es una dirección IP, donde 128.2 es el número de red y 7.9 el de la interfaz de red. Las reglas usadas para dividir una dirección de IP en su parte de red y de interfaz de red se explican abajo. El formato binario para la dirección IP 128.2.7.9 es: 10000000 00000010 00000111 00001001 Las direcciones IP son usadas por el protocolo IP(ver Internet Protocol (IP)) para definir únicamente un host en la red. Los datagramas IP(los paquetes de datos elementales intercambiados entre máquinas) se transmiten a través de alguna red física conectada a la interfaz de la máquina y cada uno de ellos contiene la dirección IP de origen y la dirección IP de destino. Para enviar un datagrama a una dirección IP de destino determinada la dirección de destino de ser traducida o mapeada a una dirección física. Esto puede requerir transmisiones en la red para encontrar la dirección física de destino(por ejemplo, en LANs el ARP("Adress Resolution Protocol", analizado en ARP("Address Resolution Protocol", se usa para traducir las direcciones IP a direcciones físicas MAC). Los primeros bits de las direcciones IP especifican como el resto de las direcciones deberían separarse en sus partes de red y de interfaz. Los términos dirección de red y netID se usan a veces en vez de número de red, pero el término formal, utilizado en RFC 1166, es número de red. Análogamente, los términos dirección de host y hostID se usan ocasionalmente en vez de número de host. Hay cinco clases de direcciones IP. Se muestran en Figura - Clases asignadas de direcciones de Internet. Figura - Clases asignadas de direcciones de Internet. Nota: Dos de los números de red de cada una de las clases A, B y C, y dos de los números de host de cada red están preasignados: los que tienen todos los bits a 0 y los que tienen todos los bits a 1. Son estudiados más abajo en Direcciones IP especiales. * Las direcciones de clase A usan 7 bits para el número de red permitiendo 126 posibles redes(veremos posteriormente que de cada par de direcciones de red y de host, dos tienen un significado especial). Los restantes 24 bits se emplean para el número de host, de modo que cada red tener hasta 16,777,214 hosts. * Las direcciones de clase B usan 14 bits para el número de red, y 16 bits para el de host, lo que supone 16382 redes de hasta 65534 hosts cada una. * Las direcciones de clase C usan 21 bits para el número de red y 8 para el de host, lo que supone 2,097,150 redes de hasta 254 hosts cada una. * Las direcciones de clase D se reservan para multicasting o multidifusión, usada para direccionar grupos de hosts en un área limitada.Ver Multicasting para más información sobre el multicasting. * Las direcciones de clase E se reservan para usos en el futuro Es obvio que una dirección de clase A sólo se asignará a redes con un elevado número de hosts, y que las direcciones de clase C son adecuadas para redes con pocos hosts. Sin embargo, esto significa que las redes de tamaño medio(aquellas con más de 254 hosts o en las que se espera que en el futuro haya más de 254 hosts) deben usar direcciones de clase IP. El número de redes de tamaño pequeño y medio ha ido creciendo muy rápidamente en los últimos años y se temía que, de haber permitido que se mantuviera este crecimiento, todas las direcciones de clase B se habrían usado para mediados de los '90. Esto es lo que se conoce como el problema del agotamiento de las direcciones IP. Este problema y cómo está siendo tratado es analizado en El problema del agotamiento de las direcciones IP. Un hecho a señalar en la división de la dirección IP en dos partes es que esta división a su vez divide en dos partes la responsabilidad de elegir una dirección IP. El número de red es asignado por el InterNIC y el de host por la autoridad que controla la red. Como veremos en la siguiente sección, el número de host puede dividirse aún más: esta división también es controlada por la autoridad propietaria de la red, y no por el InterNIC. 2.2.2 Subredes Debido al crecimiento explosivo de Internet, el uso de direcciones IP asignadas se volvió demasiado rígido para permitir cambiar con facilidad la configuración de redes locales. Estos cambios podían ser necesarios cuando: * Se instala una nueva red física. * El crecimiento del número de hosts requiere dividir la red local en dos o más redes. Para evitar tener que solicitar direcciones IP adicionales en estos casos, se introdujo el concepto de subred. El número de host de la dirección IP se subdivide de nuevo en un número de red y uno de host. Esta segunda red se denomina subred. La red principal consiste ahora en un conjunto de subredes y la dirección IP se interpreta como <número de red<número de subred<número de host La combinación del número de subred y del host suele denominarse "dirección local" o parte local". La creación de subredes se implementa de forma que es transparente a redes remotas. Un host dentro de una red con subredes es consciente de la existencia de estas, pero un host de un red distinta no lo es; sigue considerando la parte local de la dirección IP como un número de host. La división de la parte local de la dirección IP en números de subred y de host queda a libre elección del administrador local; cualquier serie de bits de la parte local se puede tomar para la subred requerida. La división se efectúa empleando una máscara de subred que es un número de 32 bits. Los bits a cero en esta máscara indican posiciones de bits correspondientes al número de host, y los que están a uno, posiciones de bits correspondientes al número de subred. Las posiciones de la máscara pertenecientes al número de red se ponen a uno pero no se usan. Al igual que las direcciones IP, las máscaras de red suelen expresarse en formato decimal. El tratamiento especial de "todos los bits a cero" y "todos los bits a uno" se aplica a cada una de las tres partes de dirección IP con subredes del mismo modo que a una dirección IP que no las tiene. Ver Direcciones IP especiales. Por ejemplo, una red de clase B con subredes, que tiene un parte local de 16 bits, podría hacer uso de uno de los siguientes esquemas: * El primer byte es el número de subred, el segundo el de host. Esto proporciona 254(256 menos dos, al estar los valores 0 y 255 reservados) posibles subredes, de 254 hosts cada una. La máscara de subred es 255.255.255.0. * Los primeros 12 bits se usan para el número de subred, y los 4 últimos para el de host. Esto proporciona 4094 posibles subredes(4096 menos 2), pero sólo 14 host por subred. La máscara de subred es 255.25.255.240. Hay muchas otras posibilidades. Mientras el administrados es totalmente libre de asignar la parte de subred a la dirección local de cualquier forma legal, el objetivo es asignar un número de bits al número de subred y el resto a la dirección local. Por tanto, es corriente usar un bloque de bits contiguos al comienzo de la parte local para el número de subred ya que así las direcciones son más legibles(esto es particularmente cierto cuando la subred ocupa 8 o 16 bits). Con este enfoque, cualquiera de las máscaras anteriores es buena, pero no máscaras como 255.255.252.252 o 255.255.255.15. 2.2.2.1 Tipos de "subnetting" Hay dos tipos de "subnetting": estático y de longitud variable. El de longitud variable es el más flexible de los dos. El tipo de "subnetting" disponible depende del protocolo de encaminamiento en uso; el IP nativo sólo soporta "subnetting" estático, al igual que el ampliamente utilizado RIP. Sin embargo, la versión 2 del protocolo RIP soporta además "subnetting" de longitud variable. Para ver una descripción de RIP y RIP2, ir a RIP("Routing Information Protocol". Protocolos de encaminamiento analiza los protocolos de encaminamiento en detalle. "Subnetting" estático El "subnetting" estático consiste en que todas las subredes de la red dividida empleen la misma máscara de red. Esto es simple de implementar y de fácil mantenimiento, pero implica el desperdicio de direcciones para redes pequeñas. Por ejemplo, una red de cuatro hosts que use una máscara de subred de 255.255.255.0 desperdicia 250 direcciones IP. Además, hace más difícil reorganizar la red con una máscara nueva. Hoy en día, casi todos los hosts y "routers" soportan "subnetting" estático. "Subnetting" de longitud variable Cuando se utiliza "subnetting" de longitud variable, las subredes que constituyen la red pueden hacer uso de diferentes máscaras de subred. Una subred pequeña con sólo unos pocos hosts necesita una máscara que permita acomodar sólo a esos hosts. Una subred con muchos puede requerir una máscara distinta para direccionar esa elevada cantidad de hosts. La posibilidad de asignar máscaras de subred de acuerdo a las necesidades individuales de cada subred ayuda a conservar las direcciones de red. Además, una subred se puede dividir en dos añadiendo un bit a la máscara. El resto de las subredes no se verán afectadas por el cambio. No todos los hosts y "routers" soportan "subnetting" de longitud variable. Sólo se dispondrán redes del tamaño requerido y los problemas de encaminamiento se resolverán aislando las redes que soporten "subnetting" de longitud variable. Un host que no soporte este tipo de "subnetting" debería disponer de una ruta de encaminamiento a un "router" que sí lo haga. Mezclando "subnetting" estático y de longitud variable A primera vista, parece que la presencia de un host que sólo puede manejar "subnetting" estático impediría utilizar "subnetting" de longitud variable en cualquier punto de la red. Afortunadamente no es este el caso. Siempre que los "routers" entre las subredes que tengan distintas máscaras usen "subnetting" de longitud variable, los protocolos de encaminamiento son capaces de ocultar la diferencia entre máscaras de subred a cada host de una subred. Los hosts pueden seguir usando encaminamiento IP básico y desentenderse de las complejidades del "subnetting", que quedan a cargo de "routers" dedicados a tal efecto. 2.2.2.2 Ejemplo de "subnetting" estático Asumamos que a nuestra red se le ha asignado el número de red IP de clase B 129.112. Tenemos que implementar múltiples redes físicas en nuestra red, y algunos de los "routers" que usaremos no admiten "subnetting" de longitud variable. Por tanto tendremos que elegir una máscara de subred para la totalidad de la red. Tenemos una dirección local de 16 bits para la red y debemos dividirla correctamente en dos partes. Por el momento, no preveremos tener más de 254 redes físicas, ni más de 254 hosts por red, de tal forma que una máscara de subred aceptable sería 255.255.255.0(que además tiene la ventaja de ser legible). Esta decisión debe tomarse cuidadosamente, ya que será difícil cambiarla posteriormente. Si el número de redes o de hosts crece por encima de nuestras previsiones, puede que tengamos que implementar "subnetting" de longitud variable para usar al máximo las 65534 direcciones locales de las que disponemos. Figura - Una configuración de subred muestra un ejemplo de implementación con tres subredes. Figura: Una configuración de subred - Tres redes físicas forman una sola red IP. Los dos "routers" realizan tareas ligeramente diferentes. El "router" 1 actúa como "router" entre las subredes 1 y 3 así como para toda nuestra red y el resto de Internet. El "router" 2 actúa sólo como "router" entre las redes 1 y 2. Consideremos ahora una máscara de subred diferente: 255.255.255.240. El cuarto octeto se ha dividido por tanto en dos partes: La siguiente tabla contiene las posibles subredes que usarían esta máscara: Tabla: Valores de subredes para la máscara de subred 255.255.255.240 Para cada uno de estos valores de subred, sólo 14 direcciones( de la 1 a la 14) de hosts están disponibles, ya que sólo la parte derecha del octeto se puede usar y porque las direcciones 0 y 15 tienen un significado especial tal como se describe en Direcciones IP especiales. De este modo, el número de subred 9.67.32.16 contendrá a los hosts cuyas direcciones IP estén en el rango de 9.67.32.17 a 9.67.32.30, y el número de subred 9.67.32.32 a los hosts cuyas direcciones IP estén en el rango de 9.67.32.33 a 9.67.32.46, etc. 2.2.2.3 Encaminamiento IP con subredes Para encaminar un datagrama IP en la red, el algoritmo general de encaminamiento IP tiene la forma siguiente: Figura: Encaminamiento IP con subredes Para ser capaz de distinguir entre subredes, el algoritmo de encaminamiento IP cambia y adopta la siguiente forma: Figura: Encaminamiento IP con subredes Algunas consecuencias de este algoritmo son: * Es un cambio a algoritmo general. Por tanto, para poder operar de este modo, la correspondiente pasarela debe contener también el nuevo algoritmo. Algunas implementaciones pueden seguir usando el algoritmo general, y no funcionarán dentro de una red con subredes, aunque todavía podrán comunicarse con hosts en otras redes que no empleen "subnetting". * Ya que el encaminamiento IP se usa en todos los hosts (aunque no en todos los "routers", todos los hosts en la subred deben: 1. Tener un algoritmo IP que soporte "subnetting". 2. Tener la misma máscara de subred(a menos que existan subredes dentro de la subred). * Si la implementación de algún host no soporta "subnetting", dicho host sólo podrá comunicarse con hosts de la propia subred, pero no con máquinas que se hallen en otra subred dentro de su misma red. Esto se debe a que el host sólo ve la red IP y su encaminamiento no puede distinguir entre un datagrama IP dirigido a un host de su subred y que se debería enviar a través de un "router" a una subred diferente. En caso de que uno o más hosts no soporten "subnetting", una forma alternativa de lograr el mismo objetivo es hacer uso del proxy-ARP, que no requiere cambios al algoritmo de encaminamiento IP para un host con una sola interfaz("single-homed", pero requiere cambios en los "routers" entre subredes. Esto se explica con más detalle en Proxy-ARP o "subnetting" transparente. 2.2.2.4 Obteniendo una máscara de subred Habitualmente, los hosts almacenan su máscara de subred en un fichero de configuración. Sin embargo, a veces esto no se puede hacer, como es el caso de estaciones de trabajo sin disco. El protocolo ICMP incluye dos mensajes, solicitud de máscara de direcciones y respuesta de máscara de direcciones, que permitirá a los hosts obtener la máscara de subred correcta de un servidor. Ver Solicitud de máscara de direcciones(17) y Respuesta de máscara de direcciones (18) para más información. 2.2.2.5 Direccionando "routers" y hosts "multi-homed" Un host se denomina "multi-homed" cuando tiene conexión física con múltiples redes o subredes . Todos los "routers" han de ser multi-homed ya que su trabajo es unir redes o subredes distintas. Un host multi-homed tiene siempre una dirección IP diferente para cada adaptador de red, puesto que cada adaptador se halla en una red distinta. Hay una excepción aparente a esta regla: con algunos sistemas(por ejemplo VM y VMS) es posible especificar la misma dirección IP para múltiples enlaces punto a punto (como es el caso de los adaptadores de canal a canal) si el protocolo de encaminamiento se limita al algoritmo básico de encaminamiento IP. 2.2.3 Direcciones IP especiales Como se ha señalado anteriormente, cualquier componente de un dirección IP con todos sus bits a 1 o a 0 tiene un significado especial todos los bits a 0 significa "este": "este" host (direcciones IP con <número de host=0) o "esta" red (direcciones IP con <número de red=0) y sólo se usa cuando el valor real no se conoce. Esta forma de expresar direcciones se utiliza con direcciones IP fuente, cuando el host trata de determinar sus direcciones IP por medio de un servidor remoto. El host puede incluir su número de host, si lo conoce, pero no su número de red o subred. Ver Protocolo BOOTstrap - BOOTP. todos los bits a 1 significa "todos": "todas" las redes o "todos" los hosts. Por ejemplo, 128.2.255.255 (una dirección de clase B con número de host 255.255) significar "todos los host de la red 128.2". Este forma de expresar direcciones se emplea en mensajes de broadcast, como se describe más abajo. Hay otra dirección de especial importancia: el número de red de clase A con todos los bits a 1, 127, se reserva para la dirección de loopback. Todo lo que se envíe a una dirección con 127 como valor del byte de mayor orden, por ejemplo 127.0.0.1, no debe encaminarse a través de la red, sino directamente del controlador de salida al de entrada. (2) 2.2.4 Unicasting, broadcasting y multicasting La mayoría de las direcciones IP se refieren a un sólo destinatario: se denomina direcciones de unicast. Sin embargo, como se ha señalado anteriormente, hay dos tipos especiales de direcciones IP que se utilizan para direccionar a múltiples destinatarios: las direcciones de broadcast y de multicast. Cualquier protocolo no orientado a conexión puede enviar mensajes de broadcast o de multicast, además de los unicast. Un protocolo orientado a conexión sólo puede usar direcciones de unicast porque la conexión existe entre un par específico de hosts. Ver TCP("Transmission Control Protocol" para más información sobre los protocolos orientados a conexión.. 2.2.4.1 Broadcasting Hay una serie de direcciones que usan para el broadcast en IP: todas manejan el convenio de que "todos los bits a 1" indica "todos". Las direcciones de broadcast nunca son válidas como direcciones fuente, sólo como direcciones de destino. Los diferentes tipos de broadcast se listan aquí: direcciones de broadcast limitado La dirección 255.255.255.255 (todos los bits a 1 en toda la dirección IP) se usa en redes que soportan broadcast, como por ejemplo redes en anillo, y se refiere a todos los host de la subred. No requiere que el host tenga conocimiento alguno de la configuración IP. Todos los host de la red local reconocerán la dirección, pero los "router" nunca enviarán el mensaje. Esta regla tiene una excepción, llamada retransmisión BOOTP. El protocolo BOOTP emplea el broadcast limitado para permitir a estaciones de trabajo sin disco contactar con un servidor BOOTP. La retransmisión BOOTP es una opción de configuración disponible en algunos "routers". Sin esta posibilidad, haría falta un servidor BOOTP en cada subred. Sin embargo, no se trata de una simple retransmisión, ya que el "router" también interviene en el desarrollo del protocolo BOOTP. Ver Protocolo BOOTstrap - BOOTP para más información al respecto. direcciones de broadcast dirigidas a red Si el número de red es un válido, la red no se subdivide en subredes y el número de host referencia todos los hosts de la red especificada, (por ejemplo, 128.2.255.255). Los "router" deberían enviar estos mensajes de broadcast a menos que están configurados para no hacerlo. Este tipo de broadcast se utiliza en solicitudes ARP (ver ARP("Address Resolution") en redes que contienen subredes. direcciones de broadcast dirigidas a subred Si el número de red y el de subred son válidos, y el de host tiene todos sus bits a 1, entonces la dirección referencia a todos los host de la subred especificada. Ya que la subred fuente y la de destino pueden tener distintas máscaras de subred, la fuente debe resolver de algún modo la máscara usada en la subred de destino. El broadcast lo efectúa realmente el "router" de subred que recibe el datagrama. direcciones de broadcast dirigidas a todas las subredes Si el número de red es válido, la red se subdivide en subredes y la parte local de la dirección tiene todos los bits a 1(por ejemplo, 128.2.255.255), y la dirección se refiere a todos los hosts en todas las subredes de la red especificada. En principio, los "router" pueden propagar broadcasts por todas las subredes, aunque no están obligados a hacerlo. En la práctica, no lo hacen; hay pocas circunstancias en las que un broadcast sea deseable, y puede causar problemas, particularmente si un host se ha configurado incorrectamente sin su máscara de subred. Considerar el derroche de recursos que se produciría si el host 9.180.214.114 en la red local clase A con subredes no fuera consciente de la existencia de esas subredes y usara 9.255.255.255 como dirección de broadcast "local" en vez de 9.180.214.255 y todos los "router" aceptaran la solicitud de enviar mensajes a todos los clientes. Si los "router" respetan todos los mensajes de broadcast dirigidos a subredes, utilizan un algoritmo llamado Retransmisión Inversa("Reverse Path Forwarding" para evitar que los mensajes de broadcast se multipliquen descontroladamente. Ver el RFC 922 para más detalles sobre este algoritmo. 2.2.4.2 Multicasting El broadcast tiene una gran desventaja: su falta de selectividad. Si un datagrama IP se difunde por broadcast a una subred, cada host de la misma lo recibirá, y tendrá que procesarlo para determinar si el destinatario está activo. Si no lo está, el datagrama IP se elimina. El multicast elimina este overhead al usar grupos de direcciones IP. Cada grupo está representado por un número de 28 bits, incluido en una dirección de clase D. Recordar que una dirección de clase D tiene el formato: De este modo, las direcciones de grupos de multicast 224.0.0.0 a 239.255.255.255. Para cada dirección multicast hay un conjunto de cero o más hosts a la escucha. Es lo que se denomina el grupo de hosts. Para que un host envíe un mensaje a ese grupo no se requiere que pertenezca a él. Hay dos clases de grupos de hosts: permanentes La dirección IP tiene una asignación permanente a través de IANA. La pertenencia a un grupo no es permanente: un host puede unirse a un grupo o dejarlo a voluntad. Los grupos asignados con carácter permanente se incluyen en STD 2 - Números asignados de Internet. Algunos importantes son: 224.0.0.0 Dirección base reservada 224.0.0.1 Todos los sistemas en esta subred 224.0.0.2 Todos los "routers" en esta subred Algunos otros ejemplos usados por el protocolo de encaminamiento OSPF(ver Versión 2 de OSPF("Open Shortest Path First Protocol") son: 224.0.0.5 Todos los "router" OSPF 224.0.0.6 "Routers" OSPF designados Una aplicación puede además determinar la dirección IP permanente de un grupo por medio del DNS (ver DNS("Domain Name System") usando el dominio mcast.net, o determinar el grupo permanente para una dirección a través de una consulta por punteros(ver Mapeando direcciones IP a nombres de dominio - Consultas por punteros) en el dominio 224.in-addr.arpa. Un grupo permanente existe aunque no tenga miembros. provisionales Cualquier grupo que no sea permanente es provisional y está disponible para ser asignado dinámicamente según las necesidades. Los grupos provisionales dejan de existir cuando el número de sus miembros se hace cero. El multicast en una sola red física que lo soporte s simple. Para unirse a un grupo, un proceso activo en un host debe informar de algún modo a sus controladores de red que desea ser parte del grupo especificado. El propio software de los controladores debe mapear la dirección de multicast a una dirección física de multicast para permitir la recepción de paquetes en esa dirección. Además, tiene que asegurarse de que el proceso receptor no recibe datagramas espúreos, chequeando la dirección de destino de la cabecera IP antes de pasarlos a la capa IP. Por ejemplo, Ethernet soporta multicast si el byte de orden superior de la dirección de 48 bytes es X'01' y además IANA posee un bloque de la dirección, consistente en las direcciones entre X'00005E000000' y X'00005EFFFFFF'. IANA ha asignado la mitad inferior de este rango para direcciones de multicast, de modo que en una LAN Ethernet hay un rango de direcciones físicas entre X'01005E000000' y X'01005E7FFFFF' usado para el multicast IP. Este rango tiene 23 bits utilizables, por lo que las direcciones de multicast de 28 bits se mapean a Ethernet tomando los 23 bits inferiores, es decir, hay 32 direcciones de multicast mapeadas sobre cada dirección Ethernet. Debido a este mapeo no unívoco, hace falta efectuar un filtrado en el controlador. Hay otras dos razones por la que se podría seguir necesitando el filtrado: * Algunos adaptadores LAN están limitados a un número finito de direcciones multicast concurrentes y si este es excedido tendrán que recibir todos los multicast. * Otros adaptadores LAN tienden a filtrar de acuerdo con un valor de una tabla de hash, lo que significa que hay una posibilidad de que el filtro tenga fugas, si dos direcciones multicast con el mismo valor de hash se usan al mismo tiempo. A pesar de la necesidad de filtrar por software de paquetes multicast, el multicast aún causa mucho menos overhead en los hosts no interesados. En particular, aquellos hosts que no estén en ningún grupo no escuchan a los mensajes con direcciones multicast y por tanto todos los mensajes multicast son filtrados por el hardware de la interfaz de red. El multicast no se limita a una sola red física. Hay dos aspectos del multicast en redes físicas a considerar: * Un mecanismo para decidir la amplitud del multicast(recordar que a diferencia del unicast y el broadcast, las direcciones de multicast cubren toda Internet). * Un mecanismo para decidir si un datagrama multicast necesita ser enviado a una red concreta. El primer problema tiene fácil solución: el datagrama multicast tiene un TTL(tiempo de vida o "Time To Live" como cualquier otro datagrama, que se decrementa con cada salto a una nueva red Cuando el TTL se decrementa a cero, el datagrama no puede ir más lejos. El mecanismo para decidir si un router debe enviar un datagrama multicast se denomina IGMP("Internet Group Management Protocol" o "Internet Group Multicast Protocol". IGMP se describe más detalle en IGMP("Internet Group Management Protocol". IGMP y el multicast se definen en el RFC 1112 - Extensiones de host para el multicast IP. Pronto la tercera parte
Efecto de Oxido con Pinturas Basicas Bueno compañeros, quiero compartir con ustedes la forma de dar efectos de oxido a nuestros computadores, esto puede ser aplicado tanto a metal como al plastico e incluso otros materiales, esta guia les mostrara los implementos necesarios para realizar esto, espero que sea de su agrado ya que algunas veces he visto en reiteradas ocaciones que han preguntado como lograr esto, pero nadie tiene respuesta alguna, espero que la utilicen y le den el uso adecuado sin dar mas lata comenzamos. Pd: las fotos no las deje tan grandes ya quee no necesitan mayor resolucion primero que todo es definir cuales seran nuestros implementos de uso. -un pincel de paleta numero 16. -Pinturas Spray anti-oxido rojo y verde reja opaco -hacemos tambien una mezcla de cera incolora con judea, y hacemos lo que conocemos como betun de judea, la ideas es que quede una mazcla en forma de pasta y con una pisca de polvo de judea ya que puede quedar demasido negro, bueno es cosa que ustedes experimente y vean cual es el resultado que obtienen -luego preparamos nuestra pieza a pintar pintamos dando una rosiada con el antioxido de tal forma que no cubra toda la superficie que desemos ya que no valdra la pena y gastremos pintura de mas.. de tal forma que quede de la siguiente manera. Luego aplicamos algunas rosiadas con la pintura verde, cosa de que sea algo medio desordenado, ustedes ven que forma o de que manera quienern que se vea el efecto. tal como se muestra en la imagen. Luego acercamos un poco la lata de pintura y aplicamos antioxido nuevamente aplicando algunas rosiadas desde una distancia de 25 a 30 cms aprox Relalizamos el mismo procedimeinto pero con la pintura verde. luego de apicar la pintra verde y definir bien ya algunas terminaciones debieramos obtener algo asi. luego que se seca nos queda algo asi. una vez que nuestra pintura este seca, a lo cual debemos esperar 1 o 2 dias para que nuestra pintura no sufra incovenientes con el siguiente paso. ahora tomamos el pincel y nuestra pasta que hemos hecho y aplicamos en las orillas primero y vamos degradando hacia adelante, cosa uqe nos quede mas oscuro en las orillas y dando pinceladas fuertes se valla desgradando nuestra pasta. Algo importante es usar solo un poco de pasta en las puntas e ir realizando el procediemeiteo anterior ya que mucha pasta puede ocacionarnos grandes problemas aqui una imagen de como va quedando el proceso de envejecimiento en bruto.. y aqui fotos con el proceso mas definido de como debiera ir quedando nuestro envejecimiento. y la imagen del proceso termiando y como debiera verse una vez que todo ha salido bien y siguiendo los pasos indicados. eso seria... muy simple, a veces las cosas simples no hacen pensar bastante.. espero que se entienda y que esta les alla sido de su agrado

Registrate y eliminá la publicidad! Todos los días de tu vida realizas tareas (como leer este articulo) que solo son posibles gracias a la existencia de los microprocesadores. Estos pequeños chips se han vuelto tan comunes que hemos dejado de notarlos. Presentes en casi todos los aparatos electrónicos de la actualidad, se fabrican de a miles de millones. Y aquí te contamos como. Cuando los transistores comenzaron a desbancar a los tubos de vacío en la mayoría de los circuitos electrónicos, el material que se empleaba para construirlos era el germanio. No mucho tiempo después comenzó a utilizarse el silicio, cuyo costo, características y abundancia lo hacían mucho más interesante. El silicio es el elemento mas abundante en la corteza terrestre (27,7%) después del oxigeno. Su uso en la electrónica se debe a sus características de semiconductor. Esto significa que, dependiendo de que materiales se le agreguen (dopándolo) puede actuar como “conductor” o como un “aislador”. Durante los últimos 40 años, este modesto material ha sido el motor que impulsa la revolución microelectrónica. Con el silicio se han construido incontables generaciones de circuitos integrados y microprocesadores, cada una reduciendo el tamaño de los transistores que lo componen. Puestos a hablar de tamaños, en la superficie de un glóbulo rojo podríamos acomodar casi 400 transistores. O, ya que estamos, se pueden poner unos 30 millones sobre la cabeza de un alfiler. Es decir, son pequeños de verdad. Pero ¿Cómo es posible fabricar algo tan pequeño? El proceso de fabricación de un microprocesador es complejísimo, y apasionante. Todo comienza con un buen puñado de arena (compuesta básicamente de silicio), con la que se fabrica un monocristal de unos 20 x 150 centímetros. Para ello, se funde el material en cuestión a alta temperatura (1370º C) y muy lentamente (10 a 40 mm por hora) se va formando el cristal. De este cristal, de cientos de kilos de peso, se cortan los extremos y la superficie exterior, de forma de obtener un cilindro perfecto. Luego, el cilindro se corta en obleas (wafer) de menos de un milímetro de espesor, utilizando una sierra de diamante. De cada cilindro se obtienen miles de wafers, y de cada oblea se fabricarán varios cientos de microprocesadores. Estas obleas son pulidas hasta obtener una superficie perfectamente plana, pasan por un proceso llamado “annealing, que consiste en un someterlas a un calentamiento extremo para remover cualquier defecto o impureza que pueda haber llegado a esta instancia. Luego de una supervisión mediante láseres capaz de detectar imperfecciones menores a una milésima de micrón, se recubren con una capa aislante formada por óxido de silicio transferido mediante deposición de vapor. De aquí en más, comienza el proceso del “dibujado” de los transistores que conformarán a cada microprocesador. A pesar de ser muy complejo y preciso, básicamente consiste en la “impresión” de sucesivas máscaras sobre el wafer, que son endurecidas mediante luz ultravioleta y atacada por ácidos encargados de remover las zonas no cubiertas por la impresión. Cada capa que se “pinta” sobre el wafer permite o bien la eliminación de algunas partes de la superficie, o la preparación para que reciba el aporte de átomos (aluminio o cobre, por ejemplo) destinados a formar parte de los transistores que conformaran el microprocesador. Dado el pequeñismo tamaño de los transistores “dibujados”, no puede utilizarse luz visible en este proceso. Efectivamente, la longitud de onda de la luz visible (380 a 780 nanómetros) es demasiado grande. Los últimos procesadores de cuatro núcleos de Intel están fabricados con un proceso de 45 nanómetros, empleando una radiación ultravioleta de longitud de onda más pequeña. Un transistor construido en tecnología de 45 manómetros tiene un ancho equivalente a unos 200 electrones. Eso da una idea de la precisión absoluta que se necesita al momento de aplicar cada una de las mascaras utilizadas durante la fabricación. Una vez que el wafer ha pasado por todo el proceso litográfico, tiene “grabados” en su superficie varios cientos de microprocesadores, cuya integridad es comprobada antes de cortarlos. Se trata de un proceso obviamente automatizado, y que termina con un wafer que tiene grabados algunas marcas en el lugar que se encuentra algún microprocesador defectuoso. La mayoría de los errores se dan en los bordes del wafer, dando como resultados chips capaces de funcionar a velocidades menores que los del centro de la oblea. Luego el wafer es cortado y cada chip individualizado. En esta etapa del proceso el microprocesador es una pequeña placa de unos pocos milímetros cuadrados, sin pines ni capsula protectora. Todo este trabajo sobre las obleas de silicio se realiza en “clean rooms” (ambientes limpios), con sistemas de ventilación y filtrado iónico de precisión, ya una pequeña partícula de polvo puede malograr un procesador. Los trabajadores de estas plantas emplean trajes estériles para evitar que restos de piel, polvo o pelo se desprendan se sus cuerpos. Cada una de estas plaquitas será dotada de una capsula protectora plástica (en algunos casos pueden ser cerámicas) y conectada a los cientos de pines metálicos que le permitirán interactuar con el mundo exterior. Cada una de estas conexiones se realiza utilizando delgadísimos alambres, generalmente de oro. De ser necesario, la capsula es dotada de un pequeño disipador térmico de metal, que servirá para mejorar la transferencia de calor desde el interior del chip hacia el disipador principal. El resultado final es un microprocesador como el que equipa nuestro ordenador. Todo el proceso descrito demora dos o tres meses en ser completado, y de cada cristal de silicio extrapuro se obtienen decenas de miles de microprocesadores. La diferencia astronómica entre el costo de la materia prima (básicamente arena) y el producto terminado (microprocesadores de cientos de dólares cada uno) se explica en el costo del proceso y la inversión que representa la construcción de la planta en que se lleva a cabo. Los trabajadores de estas plantas emplean trajes estériles. Es un proceso comparable a la fabricación de circuitos impresos. Los pines se conectan utilizando delgadísimos alambres. La "materia prima" no podría ser mas abundante. Proceso De Fabricacion: Un Poco Mas De Info: ¿Dónde se fabrica? El proceso de fabricación es llevado a cabo en los llamados laboratorios blancos, se los llama así porque el laboratorio debe estar completamente libre de cualquier posible espora de polvo, lo cual podría provocar millones de dólares de pérdidas, pero esto ya lo desarrollare mas adelante. Se estima que una de estas fabricas, pueden llegar a valer algo de 0.2 billones de euros, algo de 200.000.000.000 millones de euros. Por eso mismo son contadas, solo hay una en los EEUU, otra en Alemania, y otra en Japón . Empecemos con el proceso. Como ya dije anteriormente la materia prima es el silicio en estado puro, el cual se extrae ni mas ni menos que de arena, esta se compacta y se hornea a mas de 300º, formando cilindros, que mas adelante serán cortados en rodajas, dando como resultado los famosos waffers u obleas redondas, de un diámetro aleatorio de 200 o 300 mm. Luego las obleas se pulen hasta quedar como un espejo y del grosor de menos de 1mm, es vital que la oblea quede perfecta, sin diferencias, manchas, ni brillos. La primera técnica que vamos a ver es la oxidación, en esta es depositada un capa no conductora de oxido de silicio, llamada dieléctrico, esta se aplica en un horno a 1000º c, junto con oxigeno para provocar la oxidación claro. Pasemos a la segunda técnica, la fotolitografía. La fotolitografía es un proceso llevado a cabo mediante el grabado de la oblea por haces de luz, y una resina especial que es fotosensible, osea que reacciona con la luz. Cronológicamente: 1-Se deposita la resina sobre la oblea. 2-Se hornea para fijar la capa de resina. 3-Se utiliza una mascara como patrón para imprimir, como si tomáramos sol con la remera puesta, nos quedaría todo bronceado, menos la parte de la remera. 4-Se produce la reacción de la resina mediante la luz. 5-Se hornea nuevamente 6-se quitan los restos de las resinas con ácido nítrico. Durante la fotolitografía se producen transistores, estos son dispositivos semiconductores que tienen la capacidad de “jugar” con las corrientes, cumpliendo funciones de amplificador, oscilador, conmutador o rectificador. Estos se forman a través de un complicado proceso químico que no voy a explicar en esta guía para no confundir tanto la comprensión. La razón por la cual al principio de esta guía mencione que las salas blancas debían estar totalmente limpias, es porque una mínima espora de polvo puede arruinar todo el proceso, así como también la filtración de luz, la luz empleada en estas salas, así como las de los laboratorios fotográficos es roja, en estas debe ser amarilla. Una vez concluida la fotolitografía, los microprocesadores son cortados, obteniendo su forma redonda, desechando los bordes, ustedes dirán, ¿porque no las hacen cuadradas las obleas?, la razón es que haciéndolas redondas se obtienen obleas mas uniformes y prolijas. Con el avance de la longitud de honda de las luces, cada vez es más fácil dibujar mas transistores en un mismo espacio, lo que lleva a que entren mas procesadores en cada waffle y abaratar costos de producción, como también los micros serán mas eficientes energéticamente, y en temperatura, de ahí el termino que se utiliza cuando se habla del proceso de fabricación de 0.40 micras por ej. Seria el espacio que existe entre dos canales de comunicación entre transistores (punto medio). Luego para finalizar el proceso, el núcleo es encapsulado, con un material aislante y termodisipador. Comienzan las pruebas de resistencia y estabilidad. Es una parte muy interesante. Legados a esta etapa aunque muchos no lo crean, montones de micros son desechados por fallas en cualquiera de los procesos anteriores. banco de pruebas: Utilizare un ejemplo: AMD fabrica una oblea de athlon 1.9 ghz, pero después de las pruebas y tests de estabilidad descubren que solo el 50% logra llegar estable a los 1.9 ghz, entonces prueban su limite de clocks, supongamos que llegan a 1.7 ghz estables. Entonces esos micros serán vendidos como athlon 1.7 ghz. Entonces concluimos que todos los micros de una determinada arquitectura son hijos de una sola madre, algunos han sido mejor fabricados y otros no tanto, esa es la diferencia. <a href='http://b.t.net.ar/www/delivery/ck.php?n=a2afc290&cb=INSERT_RANDOM_NUMBER_HERE' target='_blank'><img src='http://b.t.net.ar/www/delivery/avw.php?zoneid=58&cb=INSERT_RANDOM_NUMBER_HERE&n=a2afc290' border='0' alt='' /></a>