dielp
Usuario (Argentina)
Instalar un servidor web: Apache descargas: servidor apache http://httpd.apache.org/download.cgi Un servidor web no es más que un programa que ejecuta de forma continua en un ordenador (también se utiliza el término para referirse al ordenador que lo ejecuta), manteniéndose a la espera de peticiones por parte de un cliente (un navegador de internet) y que contesta a estas peticiones de forma adecuada, sirviendo una página web que será mostrada en el navegador o mostrando el mensaje correspondiente si se detectó algún error. Instalar un servidor web en nuestro PC nos permitirá, entre otras cosas, poder montar nuestra propia página web sin necesidad de contratar hosting, probar nuestros desarrollos en local, acceder a los ficheros de nuestro ordenador desde un PC remoto (aunque para esto existen otras alternativas, como utilizar un servidor FTP) o utilizar alguno de los programas basados en web tan interesantes que están viendo la luz ultimamente. Uno de los servidores web más populares del mercado, y el más utilizado actualmente, es Apache, de código abierto y gratuito, disponible para Windows y GNU/Linux, entre otros. Su instalación es bastante sencilla, pero antes de empezar con ella te recomendaría leer, si no lo has hecho ya, el artículo sobre No-IP que comentaba para crear un subdominio que apunte a tu PC, y poder utilizar una URL del tipo Nombre.no-ip.org para acceder a éste en lugar de tener que recordar su dirección IP. Si tu IP es dinámica no te queda más remedio que leerlo y aplicarlo. Y ahora, si estás listo para comenzar, podemos empezar descargando el servidor web Apache desde la página de la Fundación del mismo nombre, haciendo click sobre el enlace Win32 Binary bajo la sección “best available version” (mejor versión disponible), asumiendo que utilizas Windows. Una vez descargado el programa de instalación, pasamos a instalar el servidor web ejecutando el archivo obtenido. Acepta la licencia y pulsa siguiente (Next) hasta que nos pregunte por el dominio, nombre de servidor y correo web del administrador del servidor. Para los dos primeros campos, introduciremos el subdominio que creamos para nuestro PC en No-IP. Rellena el campo de email del administrador con una dirección cualquiera mediante la que se puedan poner en contacto contigo. Por último, se nos pide que seleccionemos también si queremos que el servidor responda en el puerto 80 para todos los usuarios, o bien que sólo se active de forma manual, para el usuario actual, y en el puerto 8080. Lo normal es seleccionar la primera opción. Pulsa siguiente un par de veces para terminar la instalación. Una vez instalado, deberíamos ser capaces de acceder al servidor web mediante un navegador introduciendo el nombre de dominio de nuestro PC en la barra de direcciones. El navegador mostrará una página web confirmándonos que Apache se ha instalado correctamente, similar a la siguiente. Basta con copiar los archivos que queramos en la carpeta htdocs dentro del directorio donde instalamos Apache para que estos estén disponibles en el servidor. Una vez llegados a este punto sólo resta configurar el servidor para adaptarlo a nuestras necesidades. El proceso de configuración de Apache se lleva a cabo a través de una archivo de configuración en modo texto llamado httpd.conf que podemos encontrar en la carpeta conf, o bien a través del menú de inicio de Windows en Configure Apache Server -> Edit the Apache httpd.conf Configuration File. Se han escrito libros enteros sobre la configuración y uso de Apache, por lo que esto queda lejos del propósito de este artículo. Si te interesa mancharte las manos y personalizar totalmente el servidor echa un vistazo a la documentación de Apache en la web de la Fundación.
QUE ES Y COMO SE CREA UNA VPN. 1.- Introducción. 2.- ¿Qué es una VPN? 3.- Funcionamiento de una VPN. 4.- Configuración de la parte Servidor de una VPN en Windows. 5.- Configuración de la parte Cliente de una VPN en Windows. 6.- Problemas de conexión. 1.- Introducción: Hace unos años no era tan necesario conectarse a Internet por motivos de trabajo. Conforme ha ido pasado el tiempo las empresas han visto la necesidad de que las redes de área local superen la barrera de lo local permitiendo la conectividad de su personal y oficinas en otros edificios, ciudades, comunidades autónomas e incluso países. Desgraciadamente, en el otro lado de la balanza se encontraban las grandes inversiones que era necesario realizar tanto en hardware como en software y por supuesto, en servicios de telecomunicaciones que permitiera crear estas redes de servicio. Afortunadamente con la aparición de Internet, las empresas, centros de formación, organizaciones de todo tipo e incluso usuarios particulares tienen la posibilidad de crear una Red privada virtual (VPN) que permita, mediante una moderada inversión económica y utilizando Internet, la conexión entre diferentes ubicaciones salvando la distancia entre ellas. Las redes virtuales privadas utilizan protocolos especiales de seguridad que permiten obtener acceso a servicios de carácter privado, únicamente a personal autorizado, de una empresas, centros de formación, organizaciones, etc.; cuando un usuario se conecta vía Internet, la configuración de la red privada virtual le permite conectarse a la red privada del organismo con el que colabora y acceder a los recursos disponibles de la misma como si estuviera tranquilamente sentado en su oficina. 2.- ¿Qué es una VPN? La brevedad es una virtud, ya lo decía el gran Quevedo: Lo bueno, si breve, dos veces bueno. Siguiendo esa premisa trataremos de explicar brevemente que una VPN es una red virtual que se crea dentro de otra red real, como puede ser Internet. Realmente una VPN no es más que una estructura de red corporativa implantada sobre una red de recursos de carácter público, pero que utiliza el mismo sistema de gestión y las mismas políticas de acceso que se usan en las redes privadas, al fin y al cabo no es más que la creación en una red pública de un entorno de carácter confidencial y privado que permitirá trabajar al usuario como si estuviera en su misma red local. En la mayoría de los casos la red pública es Internet, pero también puede ser una red ATM o Frame Relay 3.- Funcionamiento de una VPN: Como hemos indicado en un apartado anterior, desde el punto de vista del usuario que se conecta a ella, el funcionamiento de una VPN es similar al de cualquier red normal, aunque realmente para que el comportamiento se perciba como el mismo hay un gran número de elementos y factores que hacen esto posible. La comunicación entre los dos extremos de la red privada a través de la red pública se hace estableciendo túneles virtuales entre esos dos puntos y usando sistemas de encriptación y autentificación que aseguren la confidencialidad e integridad de los datos transmitidos a través de esa red pública. Debido al uso de estas redes públicas, generalmente Internet, es necesario prestar especial atención a las cuestiones de seguridad para evitar accesos no deseados. La tecnología de túneles (Tunneling) es un modo de envío de datos en el que se encapsula un tipo de paquetes de datos dentro del paquete de datos propio de algún protocolo de comunicaciones, y al llegar a su destino, el paquete original es desempaquetado volviendo así a su estado original. En el traslado a través de Internet, los paquetes viajan encriptados, por este motivo, las técnicas de autenticación son esenciales para el correcto funcionamiento de las VPNs, ya que se aseguran a emisor y receptor que están intercambiando información con el usuario o dispositivo correcto. La autenticación en redes virtuales es similar al sistema de inicio de sesión a través de usuario y contraseña, pero tienes unas necesidades mayores de aseguramiento de validación de identidades. La mayoría de los sistemas de autenticación usados en VPN están basados en sistema de claves compartidas. La autenticación se realiza normalmente al inicio de una sesión, y luego, aleatoriamente, durante el transcurso de la sesión, para asegurar que no haya algún tercer participante que se haya podido entrometer en la conversación. Todas las VPNs usan algún tipo de tecnología de encriptación, que empaqueta los datos en un paquete seguro para su envío por la red pública. La encriptación hay que considerarla tan esencial como la autenticación, ya que permite proteger los datos transportados de poder ser vistos y entendidos en el viaje de un extremo a otro de la conexión. Existen dos tipos de técnicas de encriptación que se usan en las VPN: Encriptación de clave secreta, o privada, y Encriptación de clave pública. En la encriptación con clave secreta se utiliza una contraseña secreta conocida por todos los participantes que van a hacer uso de la información encriptada. La contraseña se utiliza tanto para encriptar como para desencriptar la información. Este tipo de sistema tiene el problema que, al ser compartida por todos los participantes y debe mantenerse secreta, al ser revelada, tiene que ser cambiada y distribuida a los participantes, lo que puede crear problemas de seguridad. La encriptación de clave pública implica la utilización de dos claves, una pública y una secreta. La primera es enviada a los demás participantes. Al encriptar, se usa la clave privada propia y la clave pública del otro participante de la conversación. Al recibir la información, ésta es desencriptada usando su propia clave privada y la pública del generador de la información. La gran desventaja de este tipo de encriptación es que resulta ser más lenta que la de clave secreta. En las redes virtuales, la encriptación debe ser realizada en tiempo real, de esta manera, los flujos de información encriptada a través de una red lo son utilizando encriptación de clave secreta con claves que son válidas únicamente para la sesión usada en ese momento. 4.- Configuración de la parte Servidor de una VPN en Windows: Es importante saber que la mayor parte de aplicaciones de este estilo trabajan usando un esquema Cliente-Servidor. Esto significa que habrá que configurar los dos extremos de la comunicación, en un extremo tendremos la máquina que va a funcionar como servidor, es decir, la máquina a la que nos vamos a conectar, y en el otro un cliente que es la que usaremos para conectarnos. Comencemos por la configuración del Servidor, y como ocurre siempre con Microsoft, para casi todas las operaciones que se pueden realizar hay un asistente que nos ayuda. Para arrancar el asistente vemos la operativa en la siguiente imagen: Pinchamos en Inicio ---> Configuración ---> Conexiones de red, lo que permitirá que aparezca la siguiente pantalla: Hacemos doble click sobre el Asistente para conexión nueva para arrancarlo: http://www2.configurarequipos.com/imgdocumentos/QueEsyComoCrearunaVPN/03.jpg Pulsamos Siguiente y nos aparecerá la siguiente pantalla: Seleccionamos la opción Configurar una conexión avanzada y volvemos a pulsar el botón siguiente que nos lleva a la siguiente pantalla: En este caso, seleccionamos la opción Aceptar conexiones entrantes y pulsamos el botón Siguiente. Aparecerá otra ventana: Aquí debemos mantener desmarcada la casilla de verificación y pulsamos de nuevo el botón Siguiente y aparecerá otra ventana: En esta ventana seleccionamos Permitir conexiones privadas virtuales, pulsamos de nuevo el botón Siguiente y pasaremos a la otra ventana: En esta ventana nos parecerán los usuarios definidos en la máquina y debemos seleccionar el que vamos a usar para acceder desde el exterior. Hemos creado un usuario nuevo desde el administrador de usuarios y le hemos asignado una contraseña. En caso de no querer usar el administrador de usuarios podemos pinchar en el botón Agregar y podremos crear uno con la contraseña que deberá usar para acceder, tal y como vemos en la siguiente imagen: Si pulsamos en el botón Aceptar nos crea la cuenta de usuario. Si no queremos crear ningún usuario o lo hemos creado previamente, sólo hay que seleccionarlo como podemos ver que ocurre en la Imagen08 con el usuario EXTERNO y a continuación pulsamos de nuevo el botón Siguiente para pasar de pantalla: En esta pantalla mantenemos activas todas las opciones y volvemos a pulsar en el botón Siguiente para terminar: Vemos la última pantalla en la que pulsamos en el botón Finalizar para crear definitivamente la conexión y cerrar el asistente. Una vez finalizado el proceso, en la pantalla Conexiones de red veremos creada la nueva conexión que hemos resaltado en color verde para destacarla. En lo que se refiere a la parte servidora, es decir la máquina a la que vamos a acceder, podemos dar por terminada la configuración, aunque es cierto que si el equipo se encuentra en una red interna y detrás de un router habrá que realizar el mapeo de puertos para que la conexión funcione y además habrá que tener en cuenta que si tenemos activado el Firewall debemos marcar la casilla Conexión entrante VPN (PPTP) para que no quede bloqueada. Mencionaremos que el puerto de trabajo para el protocolo PPTP es el 1723, que será el que debemos incluir en la configuración del router. No damos detalles sobre cómo realizar esta operación ya que depende del modelo de router que se use. También destacar que el número de protocolo que corresponde al PPTP es el 47. Si usamos L2TP el puerto a configurar es el 1701. Si se va a utilizar además IPSec, se debe abrir el puerto UDP 500 y los protocolos de Id. 50 (IPSec ESP) y 51 (IPSec AH). 5.- Configuración de la parte Cliente de una VPN en Windows: Una vez configurado el servidor vamos a ver como se configura la parte cliente en el ordenador desde el que vamos a acceder. Para empezar hacemos lo mismo que en el caso del servidor, arrancando el asistente de configuración tal y como describimos en el apartado anterior en las imágenes Imagen01, Imagen02 y Imagen03. Pinchamos en Inicio ---> Configuración ---> Conexiones de red, hacemos doble click sobre el Asistente para conexión nueva para arrancarlo, pulsamos Siguiente y nos aparecerá la pantalla que vemos a continuación: Seleccionamos la opción de Conectarsea la red de mi lugar de trabajo y pulsamos en el botón Siguiente para avanzar: Seleccionamos la opción de Conexión de red privada virtual y pulsamos en el botón Siguiente para avanzar: En esta pantalla vamos a asignarle un nombre a la conexión y de nuevo pulsamos en el botón Siguiente para avanzar: Vemos que nos aparece una caja de texto para que pongamos la dirección IP que tendrá en internet el servidor al que nos queremos conectar de tal forma que NNN.NNN.NNN.NNN serán los número que forman esa dirección IP por ejemplo, 83.83.84.185 si fuera el caso. A continuación pulsamos en el botón Siguiente para avanzar: Seleccionamos la opción Sólo para mi uso y volvemos a pulsar en el botón Siguiente para avanzar, apareciendo esta última ventana: En la que podemos elegir si queremos un acceso directo a la conexión en el propio escritorio y a continuación pulsamos en el botón Finalizar para crear definitivamente la conexión y cerrar el asistente. Una vez finalizado el proceso, en la pantalla Conexiones de red veremos creada la nueva conexión: Si hacemos doble click sobre ella se nos abrirá la siguiente ventana Como vemos hay que introducir los datos del usuario que autorizamos al configurar la parte servidora y la contraseña corresponderá a la misma que se le estableció en el momento de su creación. Pinchamos en el botón Conectar y vemos como inicia las comunicaciones. Si todo ha ido bien conectaremos con el servidor y podremos trabajar con él si problemas. 6.- Problemas de conexión: Desgraciadamente, en esto de la informática, al igual que en otros aspecto de la vida, no todo sale a la primera como nosotros esperamos y podemos encontrarnos con problemas. Como ejemplo podemos ver la imagen que aparece a continuación El resultado es que no podemos conectar con el servidor, en este caso, los aspectos de configuración que debemos revisar son los siguientes: - Puede que la dirección del servidor no sea la correcta. - Es posible que haya un componente de la red (router, firewall o software de seguridad) que esté bloqueando el tráfico PPtP. Si nos encontramos en el primer caso, habrá que poner el identificador del servidor correctamente, si la dirección IP con la que queremos conectar es una dirección IP dinámica, puede que ésta haya sido modificada desde la última vez que accedimos. Deberemos conocer dicha IP en el momento de iniciar la conexión para evitar el error para solucionar este problema, desde la ventana de conexión podemos modificarlo pinchamos en el botón Propiedades que nos permite acceder a la siguiente ventana: En esta ventana podemos modificar la IP del servidor con el que vayamos a conectar en caso de que no la hayamos puesto correctamente o haya cambiado desde la última conexión en el resto de pestañas se pueden configurar otros aspectos de la conexión. En caso de que las comunicaciones se encuentren bloqueados por algún elemento hardware o software de la red, bastará con ir cuidadosamente comprobándolos uno a uno hasta dar con el problema. fuente: http://www.configurarequipos.com/doc499.html

1. ¿Qué es Webalizer? Webalizer es un pequeño programa hecho en C el cual nos permite generar reportes de alguna página web. Gracias a esos reportes, podemos observar el número de personas que han entrado en la web donde se vaya a instalar(o ejecutar) el webalizer y muchas otras cosas que más adelante les detallaré. Este programa no sólo nos da los reportes cuantitativos, si no que también nos da repostes gráficos, lo que hace mas elegante y sencillo de observar las estadísticas de nuestra página web. Entre otras cosas webalizar es sumamente útil para saber que archivos son los que poseen más número de descargas en nuestra página web. 2. ¿Cómo funciona Webalizer? Es muy sencillo de entender como funciona el webalizer por lo que nos resultará trivial de aprender. Vamos a empezar con algunos conceptos básicos que deberíamos de tener claro. Cuando poseemos una página web y cualquier persona de la internet accede a esta eso siempre queda registrado en una bitácora, que comúnmente se le denomina "logs". Por ejemplo, al yo entrar al www.mogaal.com desde cualquier navegador en cualquier computadora del mundo, el servidor web registra mi ingreso a dicha página web, este ingreso lo registra o guarda en un archivo(una "bitácora" o "logs" que en la mayoría de los servidores web (específicamente en apache) es un archivo llamado access.log. Una vez que esas bitácoras del sistema quedan registradas en una archivo llamado access.log, el programa Webalizer analiza esos logs y genera unas gráficas en formato HTML para que puedan ser observadas desde el navegador. Específicamente el lo que hace es leer el formato del archivo de bitácoras(access.log), todos esos datos los analiza y seguidamente genera un archivo .html (archivo que es interpretado por el navegador) que va a poder ser accesible desde la web. Este archivo HTML, tiene reportes con gráficas de todos lo que ha sido el número de visitas, tráfico, archivos ofrecidos, el tipo de navegadores web que mas visita nuestra página, etc. 3. Instalándolo Webalizer Tenemos tres maneras de hacer funcionar el webalizer, la primera es descargándonos el código fuente de la página web oficial de webalizer y compilándolo. La segunda manera es descargando los binarios y ejecutándolos. La tercera manera es para las personas que poseen un sistema operativo como Debian o derivados de este, donde es posible instalar en paquete llamado webalizer que se encuentra en los repositorios oficiales de Debian. Nosotros nos vamos a guiar por la tercera opción por cuestiones de simplicidad, si deseas compilarlo descarga el código fuente y sigue las instrucciones del fichero INSTALL. Para instalar webalizer en Debian lo único que debemos hacer es ejecutar: # aptitude install webalizer Una vez ejecutado ese comando el aptitude( o apt-get) hace todo por nosotros, es decir, lo descarga, instala y configura(configuración que editaremos posteriormente). Cuando se termina de instalar el gestor de paquetes aptitude nos hará unas preguntas, yo recomiendo que las obvies, ya que nosotros analizaremos y explicaremos como configurar el webalizer posteriormente. Entonces si mientras se instala el webalizer te empieza a hacer preguntas tu sólo trata de presionar enter obviando las preguntas. Si deseas responderlas puedes hacerlo y el generará un archivo de configuración en base a las preguntas que has respondido. ¿Cómo verifico que la instalación fue correcta? Una manera es verificar que exista el comando webalizer. En una consola escribe webalizer y si obtienes un mensaje tipo command not found es que no se instaló correctamente por lo que debes verificar si hubo algún fallo. 4. Configurando Webalizer Si estás en Debian el archivo de configuración de webalizer está en el directorio /etc, si no estás en Debian, el archivo de configuración está en el directorio donde lo compilaste, es un archivo de ejemplo, pero es muy factible adaptarlo para usarlo como guía a la hora de generar el nuestro. El archivo de configuración lo puedes editar con cualquier editor de archivos. El nombre de este archivo es webalizer.conf. Nuestro archivo debe lucir algo parecido al siguiente: ARCHIVO DE CONFIGURACIÓN. Has Click AQUÍ para descargarlo LogFile /var/log/apache2/access.log OutputDir /var/www/webalizer Incremental yes ReportTitle Estidísticas de PAGINAWEB_NOMBRE Hostname URL_PAGINA IgnoreSite localhost "LogFile /var/log/apache2/access.log". Aquí es donde especificamos el lugar donde se encuentran las bitácoras de las personas que acceden a nuestra web, esas bitácoras las guarda nuestro servidor web. Si usamos apache normalmente esas están ubicadas en el directorio '/var/log/apache2' y el nombre del fichero que las guarda es access.log. El Webalizer necesita saber dónde están esas bitácoras para saber quienes han entrado, con que navegadores y muchas otras cosas mas. "OutputDir /var/www/webalizer" : Es obvio que tengamos que especificar el directorio donde se generaran los archivos HTML que contendrán las estadísticas y reportes de nuestra página web, lo más lógico es que sea en un lugar accesible desde la web. Como la mayoría de los contenidos web se colocan en '/var/www' por lo que he creado un directorio ahí llamado webalizer, ahí es donde se generarán los registros HTML. "Incremental yes" : Esta opción nos permite que webalizer analice todo por separado. Para hacerlo mas entendible hay que comprender que algunos servidores web (por ejemplo apache) parten sus bitácoras, por ejemplo, mensualmente crean un nuevo archivo de bitácoras y renombran el otro con un nombre nuevo. Si usas apache es normal que por ejemplo cada mes o cada cierto tiempo tu access.log lo renombren a access.log.1 y se cree un nuevo access.log vacío donde se guardarán los próximos nuevos registros. Bueno está opción que nos ofrece Webalizer es que el va a seguir tomando en cuenta los archivos ya renombrados, como también los nuevos archivos. "ReportTitle Estadísticas de PAGINAWEB_NOMBRE" : Creo que está opción no hay mucho que explicarla, es evidente que se trata del título que quieres que lleve las páginas HTML que se generarán. "HostName URL_PAGINA" : Aquí se coloca el Nombre o URL del servidor donde está el webalizer. Este Nombre normalmente aparece al lado del título de Reportes (ReportTitle). En pocas palabras concatenan ReportTitle y HostName. También se usa para los enlaces desde Webalizer a las páginas ofrecidas. Mas adelante podrás observar mejor esto. "IgnoreSite localhost" : Esto lo que hace es ignorar o no tomar en cuenta los registros que vengan de la computadora local. Si no colocamos está opción cada vez que nosotros mismos desde la máquina en que está el servidor web visitáramos la página se registraría ese acceso y muchas veces no queremos esto. ¿Por qué? Porque normalmente hacemos prácticas de diseño o modificación de la página web lo que ocasiona que estamos entrando a la página web y si obviamos esta opción estaríamos haciendo reportes o estadísticas de _cuantas veces_ nosotros mismos estamos entramos a la página(lo cual no queremos eso). ¿Son estas las únicas opciones que tiene que llevar el archivo de Webalizer? No, de hecho son las mínimas que considero que debería de llevar. Estamos ignorando algunas de las opciones básicas que debe de llevar, como por ejemplo(recomiendo colocarlas): -HideURL *.gif -HideURL *.GIF -HideURL *.jpg -HideURL *.JPG -HideURL *.ra Si se fijan aquí lo que le estamos indicando en el archivo de configuración de webalizer es que no tome en cuenta las imágenes con extensión GIF y JPG. Lo que pasa en realidad es que Webalizer en su interfaz nos muestra todas las páginas ofrecidas, y muchas veces tenemos imágenes en nuestro servidor web que no quisiéramos mostrar o no quisiéramos que nadie se entere de que están ahí. Recomiendo que para aprender mas acerca de que cosas que puedes incluir en el archivo de configuración de webalizer leas la documentación oficial. 5. Generando los Reportes Ya hemos analizado algunas de las opciones que permite hacer trabajar correctamente al programa. Como ya mensionamos webalizer genera los reportes en u formato HTML que podemos observar en un navegador, pero el sólo genera estos reportes las veces que ejecutemos el programa. Por lo tanto tendríamos que estar ejecutando el programa cada vez que queramos que generar o actualizar los reportes ya existentes. ¿Resulta esto muy tedioso no? En Linux y en los todos los sistemas derivados de Unix existe una herramienta llamada cron, que nos saca la pata del barro como en casos como estos. El cron lo que hace es ejecutar tareas en intervalos de tiempo especificados por el usuario. En nuestra situación utilizaríamos el cron para ejecutar el comando que genera los registros o reportes HTML, de manera que estaríamos actualizando los reportes en un intervalo de tiempo especificado por nosotros, y todo esto gracias a cron. Para nosotros poder generar los registros tenemos que usar el comando webalizer(el programa como tal). El comando con sus opciones y argumentos es el siguiente: Comando: $ webalizer -c /etc/webalizer.conf -d Primeramente llamamos al programa que hará los reportes, lógicamente es webalizer, la opción -c le indica al webalizer que tome el archivo de configuración que se encuentra en /etc/webalizer.conf, y la opción -d le indica que haga debugging mientras genera los reportes, es decir, que nos indique si hubo algún error o si todo salió bien. ¿Cómo le indicamos al webalizer donde generar los archivos HTML? Si observas detenidamente le estamos indicando con la opción -c que elija un archivo de configuración ubicado en /etc/webalizer.conf, y es en ese archivo es el que nosotros editamos y modificamos, es decir, donde fuimos especificando toda esa serie de parámetros y entre ellos el lugar donde se generarán los reportes HTML. Ya con esté comando ejecutado podríamos entrar a una navegador y ver esas estadísticas, pero resulta incómodo estar ejecutando ese comando cada vez que queramos actualizar los reportes, y es aquí donde esta a ayudarnos el cron. Lo que tenemos que hacer para poder utilizar el cron es editar el su archivo de configuración(/etc/crontab) y agregar la siguiente linea: 0 0 * * * /usr/bin/webalizer -c /etc/webalizer.conf -d Aquí lo que le estamos diciendo es que ejecute ese comando todos los días a la media noche. Por lo que deducimos que los reportes se estarán actualizando todos los días del año a la media noche 6. TIPS y FAQ Unos de los típicos problemas que se presentan son: Problema: "Poseo un gran número páginas web y el webalizer me hace las estadísticas de todas ellas ya que analiza un único archivo de bitácora del sistema" Respuesta: Aquí lo que debes de hacer es configurar tu servidor web para que genere varios archivos de bitácoras, es decir, que me genere un logfile(access.log) por cada página web. Problema: "Cuando son necesarios los Binarios y cuando es necesario compilarlo". Respuesta: El compilar un programa hace que sea un poco mas rápido, pero es solo _un poco_. Pero la principal razón para elegir entre binarios y descargar el código fuente para compilarlo es cuando estamos en un servidor compartido, es decir no tenemos total control del sistema. Si nosotros queremos compilar he instalar un programa necesitamos ser el administrador del sistema (usuario root) y no todos tenemos esa ventaja de tener acceso como usuario administrador. Por ejemplo en mi caso, tengo acceso a un servidor compartido pero no tengo cuenta de usuarios root ni tampoco está instalado webalizer. En este caso es conveniente descargarse los binarios y ejecutarlos _en vez_ de compilarlo he instalarlo. 7. Copyrigth y licencia Copyright (c) 2006 Alejandro Garrido Mota. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". fuente: http://mogaal.com/articulos/webalizer/webalizer.html
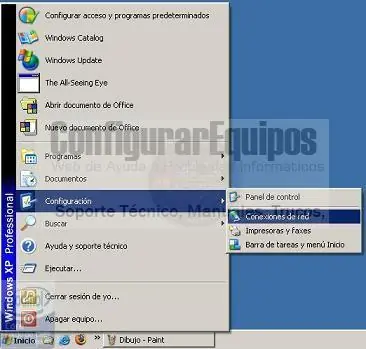
QUE ES Y COMO SE CREA UNA VPN. 1.- Introducción. 2.- ¿Qué es una VPN? 3.- Funcionamiento de una VPN. 4.- Configuración de la parte Servidor de una VPN en Windows. 5.- Configuración de la parte Cliente de una VPN en Windows. 6.- Problemas de conexión. 1.- Introducción: Hace unos años no era tan necesario conectarse a Internet por motivos de trabajo. Conforme ha ido pasado el tiempo las empresas han visto la necesidad de que las redes de área local superen la barrera de lo local permitiendo la conectividad de su personal y oficinas en otros edificios, ciudades, comunidades autónomas e incluso países. Desgraciadamente, en el otro lado de la balanza se encontraban las grandes inversiones que era necesario realizar tanto en hardware como en software y por supuesto, en servicios de telecomunicaciones que permitiera crear estas redes de servicio. Afortunadamente con la aparición de Internet, las empresas, centros de formación, organizaciones de todo tipo e incluso usuarios particulares tienen la posibilidad de crear una Red privada virtual (VPN) que permita, mediante una moderada inversión económica y utilizando Internet, la conexión entre diferentes ubicaciones salvando la distancia entre ellas. Las redes virtuales privadas utilizan protocolos especiales de seguridad que permiten obtener acceso a servicios de carácter privado, únicamente a personal autorizado, de una empresas, centros de formación, organizaciones, etc.; cuando un usuario se conecta vía Internet, la configuración de la red privada virtual le permite conectarse a la red privada del organismo con el que colabora y acceder a los recursos disponibles de la misma como si estuviera tranquilamente sentado en su oficina. 2.- ¿Qué es una VPN? La brevedad es una virtud, ya lo decía el gran Quevedo: Lo bueno, si breve, dos veces bueno. Siguiendo esa premisa trataremos de explicar brevemente que una VPN es una red virtual que se crea dentro de otra red real, como puede ser Internet. Realmente una VPN no es más que una estructura de red corporativa implantada sobre una red de recursos de carácter público, pero que utiliza el mismo sistema de gestión y las mismas políticas de acceso que se usan en las redes privadas, al fin y al cabo no es más que la creación en una red pública de un entorno de carácter confidencial y privado que permitirá trabajar al usuario como si estuviera en su misma red local. En la mayoría de los casos la red pública es Internet, pero también puede ser una red ATM o Frame Relay 3.- Funcionamiento de una VPN: Como hemos indicado en un apartado anterior, desde el punto de vista del usuario que se conecta a ella, el funcionamiento de una VPN es similar al de cualquier red normal, aunque realmente para que el comportamiento se perciba como el mismo hay un gran número de elementos y factores que hacen esto posible. La comunicación entre los dos extremos de la red privada a través de la red pública se hace estableciendo túneles virtuales entre esos dos puntos y usando sistemas de encriptación y autentificación que aseguren la confidencialidad e integridad de los datos transmitidos a través de esa red pública. Debido al uso de estas redes públicas, generalmente Internet, es necesario prestar especial atención a las cuestiones de seguridad para evitar accesos no deseados. La tecnología de túneles (Tunneling) es un modo de envío de datos en el que se encapsula un tipo de paquetes de datos dentro del paquete de datos propio de algún protocolo de comunicaciones, y al llegar a su destino, el paquete original es desempaquetado volviendo así a su estado original. En el traslado a través de Internet, los paquetes viajan encriptados, por este motivo, las técnicas de autenticación son esenciales para el correcto funcionamiento de las VPNs, ya que se aseguran a emisor y receptor que están intercambiando información con el usuario o dispositivo correcto. La autenticación en redes virtuales es similar al sistema de inicio de sesión a través de usuario y contraseña, pero tienes unas necesidades mayores de aseguramiento de validación de identidades. La mayoría de los sistemas de autenticación usados en VPN están basados en sistema de claves compartidas. La autenticación se realiza normalmente al inicio de una sesión, y luego, aleatoriamente, durante el transcurso de la sesión, para asegurar que no haya algún tercer participante que se haya podido entrometer en la conversación. Todas las VPNs usan algún tipo de tecnología de encriptación, que empaqueta los datos en un paquete seguro para su envío por la red pública. La encriptación hay que considerarla tan esencial como la autenticación, ya que permite proteger los datos transportados de poder ser vistos y entendidos en el viaje de un extremo a otro de la conexión. Existen dos tipos de técnicas de encriptación que se usan en las VPN: Encriptación de clave secreta, o privada, y Encriptación de clave pública. En la encriptación con clave secreta se utiliza una contraseña secreta conocida por todos los participantes que van a hacer uso de la información encriptada. La contraseña se utiliza tanto para encriptar como para desencriptar la información. Este tipo de sistema tiene el problema que, al ser compartida por todos los participantes y debe mantenerse secreta, al ser revelada, tiene que ser cambiada y distribuida a los participantes, lo que puede crear problemas de seguridad. La encriptación de clave pública implica la utilización de dos claves, una pública y una secreta. La primera es enviada a los demás participantes. Al encriptar, se usa la clave privada propia y la clave pública del otro participante de la conversación. Al recibir la información, ésta es desencriptada usando su propia clave privada y la pública del generador de la información. La gran desventaja de este tipo de encriptación es que resulta ser más lenta que la de clave secreta. En las redes virtuales, la encriptación debe ser realizada en tiempo real, de esta manera, los flujos de información encriptada a través de una red lo son utilizando encriptación de clave secreta con claves que son válidas únicamente para la sesión usada en ese momento. 4.- Configuración de la parte Servidor de una VPN en Windows: Es importante saber que la mayor parte de aplicaciones de este estilo trabajan usando un esquema Cliente-Servidor. Esto significa que habrá que configurar los dos extremos de la comunicación, en un extremo tendremos la máquina que va a funcionar como servidor, es decir, la máquina a la que nos vamos a conectar, y en el otro un cliente que es la que usaremos para conectarnos. Comencemos por la configuración del Servidor, y como ocurre siempre con Microsoft, para casi todas las operaciones que se pueden realizar hay un asistente que nos ayuda. Para arrancar el asistente vemos la operativa en la siguiente imagen: Pinchamos en Inicio ---> Configuración ---> Conexiones de red, lo que permitirá que aparezca la siguiente pantalla: Hacemos doble click sobre el Asistente para conexión nueva para arrancarlo: http://www2.configurarequipos.com/imgdocumentos/QueEsyComoCrearunaVPN/03.jpg Pulsamos Siguiente y nos aparecerá la siguiente pantalla: Seleccionamos la opción Configurar una conexión avanzada y volvemos a pulsar el botón siguiente que nos lleva a la siguiente pantalla: En este caso, seleccionamos la opción Aceptar conexiones entrantes y pulsamos el botón Siguiente. Aparecerá otra ventana: Aquí debemos mantener desmarcada la casilla de verificación y pulsamos de nuevo el botón Siguiente y aparecerá otra ventana: En esta ventana seleccionamos Permitir conexiones privadas virtuales, pulsamos de nuevo el botón Siguiente y pasaremos a la otra ventana: En esta ventana nos parecerán los usuarios definidos en la máquina y debemos seleccionar el que vamos a usar para acceder desde el exterior. Hemos creado un usuario nuevo desde el administrador de usuarios y le hemos asignado una contraseña. En caso de no querer usar el administrador de usuarios podemos pinchar en el botón Agregar y podremos crear uno con la contraseña que deberá usar para acceder, tal y como vemos en la siguiente imagen: Si pulsamos en el botón Aceptar nos crea la cuenta de usuario. Si no queremos crear ningún usuario o lo hemos creado previamente, sólo hay que seleccionarlo como podemos ver que ocurre en la Imagen08 con el usuario EXTERNO y a continuación pulsamos de nuevo el botón Siguiente para pasar de pantalla: En esta pantalla mantenemos activas todas las opciones y volvemos a pulsar en el botón Siguiente para terminar: Vemos la última pantalla en la que pulsamos en el botón Finalizar para crear definitivamente la conexión y cerrar el asistente. Una vez finalizado el proceso, en la pantalla Conexiones de red veremos creada la nueva conexión que hemos resaltado en color verde para destacarla. En lo que se refiere a la parte servidora, es decir la máquina a la que vamos a acceder, podemos dar por terminada la configuración, aunque es cierto que si el equipo se encuentra en una red interna y detrás de un router habrá que realizar el mapeo de puertos para que la conexión funcione y además habrá que tener en cuenta que si tenemos activado el Firewall debemos marcar la casilla Conexión entrante VPN (PPTP) para que no quede bloqueada. Mencionaremos que el puerto de trabajo para el protocolo PPTP es el 1723, que será el que debemos incluir en la configuración del router. No damos detalles sobre cómo realizar esta operación ya que depende del modelo de router que se use. También destacar que el número de protocolo que corresponde al PPTP es el 47. Si usamos L2TP el puerto a configurar es el 1701. Si se va a utilizar además IPSec, se debe abrir el puerto UDP 500 y los protocolos de Id. 50 (IPSec ESP) y 51 (IPSec AH). 5.- Configuración de la parte Cliente de una VPN en Windows: Una vez configurado el servidor vamos a ver como se configura la parte cliente en el ordenador desde el que vamos a acceder. Para empezar hacemos lo mismo que en el caso del servidor, arrancando el asistente de configuración tal y como describimos en el apartado anterior en las imágenes Imagen01, Imagen02 y Imagen03. Pinchamos en Inicio ---> Configuración ---> Conexiones de red, hacemos doble click sobre el Asistente para conexión nueva para arrancarlo, pulsamos Siguiente y nos aparecerá la pantalla que vemos a continuación: Seleccionamos la opción de Conectarsea la red de mi lugar de trabajo y pulsamos en el botón Siguiente para avanzar: Seleccionamos la opción de Conexión de red privada virtual y pulsamos en el botón Siguiente para avanzar: En esta pantalla vamos a asignarle un nombre a la conexión y de nuevo pulsamos en el botón Siguiente para avanzar: Vemos que nos aparece una caja de texto para que pongamos la dirección IP que tendrá en internet el servidor al que nos queremos conectar de tal forma que NNN.NNN.NNN.NNN serán los número que forman esa dirección IP por ejemplo, 83.83.84.185 si fuera el caso. A continuación pulsamos en el botón Siguiente para avanzar: Seleccionamos la opción Sólo para mi uso y volvemos a pulsar en el botón Siguiente para avanzar, apareciendo esta última ventana: En la que podemos elegir si queremos un acceso directo a la conexión en el propio escritorio y a continuación pulsamos en el botón Finalizar para crear definitivamente la conexión y cerrar el asistente. Una vez finalizado el proceso, en la pantalla Conexiones de red veremos creada la nueva conexión: Si hacemos doble click sobre ella se nos abrirá la siguiente ventana Como vemos hay que introducir los datos del usuario que autorizamos al configurar la parte servidora y la contraseña corresponderá a la misma que se le estableció en el momento de su creación. Pinchamos en el botón Conectar y vemos como inicia las comunicaciones. Si todo ha ido bien conectaremos con el servidor y podremos trabajar con él si problemas. 6.- Problemas de conexión: Desgraciadamente, en esto de la informática, al igual que en otros aspecto de la vida, no todo sale a la primera como nosotros esperamos y podemos encontrarnos con problemas. Como ejemplo podemos ver la imagen que aparece a continuación El resultado es que no podemos conectar con el servidor, en este caso, los aspectos de configuración que debemos revisar son los siguientes: - Puede que la dirección del servidor no sea la correcta. - Es posible que haya un componente de la red (router, firewall o software de seguridad) que esté bloqueando el tráfico PPtP. Si nos encontramos en el primer caso, habrá que poner el identificador del servidor correctamente, si la dirección IP con la que queremos conectar es una dirección IP dinámica, puede que ésta haya sido modificada desde la última vez que accedimos. Deberemos conocer dicha IP en el momento de iniciar la conexión para evitar el error para solucionar este problema, desde la ventana de conexión podemos modificarlo pinchamos en el botón Propiedades que nos permite acceder a la siguiente ventana: En esta ventana podemos modificar la IP del servidor con el que vayamos a conectar en caso de que no la hayamos puesto correctamente o haya cambiado desde la última conexión en el resto de pestañas se pueden configurar otros aspectos de la conexión. En caso de que las comunicaciones se encuentren bloqueados por algún elemento hardware o software de la red, bastará con ir cuidadosamente comprobándolos uno a uno hasta dar con el problema. fuente: http://www.configurarequipos.com/doc499.html
Hace rato no hacía recopilaciones de sitios web, por eso hoy preparé un pequeño listado de 10 sitios web desde donde podremos descargar miles de aplicaciones gratuitas (y también de pago). Softonic http://www.softonic.com: uno de los sitios de descarga más conocidos por los hispanohablantes. Tiene miles de programas gratuitos para Windows, Linux, Mac OSX y móviles. Se puede comentar y leer los comentarios de otros usuarios, ordenar los programas por varios criterios y mucho más. Esta disponible en varios idiomas entre ellos el español. Download.com http://download.cnet.com/windows/: si duda es el sitio de descargas por excelencia. Cuenta con una gran cantidad de programas para Windows, Mac OSX, móviles y aplicaciones online. En este sitio encontraremos además completísimos reviews de aplicaciones, noticias, nuevos lanzamientos y mucho más. Solo está disponible en Inglés. Alternativeto http://alternativeto.net/: esta es la web de descargas que más me gusta ya que tiene algo que ninguno de los otros sitios tiene: nos permite seleccionar una aplicación y buscar software alternativo. Por ejemplo en mi caso, busco una aplicación x existente en Windows y Alternativeto me da un listado de aplicaciones similares que puedo usar en Linux. Solo está disponible en inglés. Snapfileshttp://www.snapfiles.com/: miles de aplicaciones gratuitas listas para descargar. También encontraremos reviews realizados por los usuarios y una completa tienda para comprar software con descuentos de hasta el 70%. Solo está disponible en inglés. Brothersofthttp://www.snapfiles.com/: otro sitio de descargas bastante conocido en donde no solo encontraremos software para Windows y Mac OSX sino que también hay aplicaciones para teléfonos móviles, drivers, juegos y fondos de pantalla. Brothersoft tiene un diseño muy agradable y está disponible en varios idiomas, entre ellos el español. Freedownloadscenterhttp://www.freedownloadscenter.com/: es el único sitio de este listado que solo recopila software gratuito. En el momento cuentan con más de 30.000 aplicaciones para windows perfectamente organizadas en varias categorías. Solo está disponible en inglés. Filehippohttp://www.filehippo.com/es/: una excelente web desde donde podremos descargar miles de aplicaciones gratuitas para nuestra PC. Además cuenta con una aplicación especial nos permite verificar si existen actualizaciones de los programas que tenemos instalados en nuestra computadora. Tiene versión en español. Thedownloadplanethttp://www.thedownloadplanet.com/: creo que es el menos conocido de los sitios de esta recopilación. Tiene un diseño un poco antiguo pero eso no quiere decir que no sea una web para tener en cuenta. Cuenta con miles de aplicaciones gratuitas para Windows organizadas en varias categorías. También podemos econtrar reviews de las aplicaciones, dejar nuestros comentarios y mucho más. No tiene versión en español. Softpediahttp://www.softpedia.com/es/: un sitio de descargas muy completo. Tiene miles de aplicaciones para Windows, Mac OSX y drivers. Además podemos encontrar las últimas noticias tecnológicas y realizar descargas de varias aplicaciones al mismo tiempo. Esta disponible en varios idiomas, entre ellos el español. Tucowshttp://www.tucows.com/index.html: en este sitio encontaremos aplicaciones gratuitas para Windows, Linux y Mac OSX además de aplicaciones web y para teléfonos móviles. También podemos encontrar video tutoriales, comprar dominios y mucho más. No tiene versión en español. Conoces algún otro sitio de descarga? Dejame el enlace en un comentario para que pueda agregarlo a este listado! Fuente: Internet!
Introducción. ¿Qué es Servidor Intermediario ( Proxy )? El término en ingles «Proxy» tiene un significado muy general y al mismo tiempo ambiguo, aunque invariablemente se considera un sinónimo del concepto de «Intermediario». Se suele traducir, en el sentido estricto, como delegado o apoderado (el que tiene el que poder sobre otro). Un Servidor Intermediario ( Proxy ) se define como una computadora o dispositivo que ofrece un servicio de red que consiste en permitir a los clientes realizar conexiones de red indirectas hacia otros servicios de red . Durante el proceso ocurre lo siguiente: • Cliente se conecta hacia un Servidor Intermediario ( Proxy ). • Cliente solicita una conexión, fichero u otro recurso disponible en un servidor distinto. • Servidor Intermediario ( Proxy ) proporciona el recurso ya sea conectándose hacia el servidor especificado o sirviendo éste desde un caché. • En algunos casos el Servidor Intermediario ( Proxy ) puede alterar la solicitud del cliente o bien la respuesta del servidor para diversos propósitos. Los Servidores Intermediarios (Proxies) generalmente se hacen trabajar simultáneamente como muro cortafuegos operando en el Nivel de Red , actuando como filtro de paquetes, como en el caso de iptables, o bien operando en el Nivel de Aplicación, controlando diversos servicios, como es el caso de TCP Wrapper. Dependiendo del contexto, el muro cortafuegos también se conoce como BPD o Border Protection Device o simplemente filtro de paquetes. Una aplicación común de los Servidores Intermediarios (Proxies) es funcionar como caché de contenido de Red (principalmente HTTP), proporcionando en la proximidad de los clientes un caché de páginas y ficheros disponibles a través de la Red en servidores HTTP remotos, permitiendo a los clientes de la red local acceder hacia éstos de forma más rápida y confiable. Cuando se recibe una petición para un recurso de Red especificado en un URL (Uniform Resource Locator) el Servidor Intermediario busca el resultado del URL dentro del caché. Si éste es encontrado, el Servidor Intermediario responde al cliente proporcionado inmediatamente el contenido solicitado. Si el contenido solicitado no estuviera disponible en el caché, el Servidor Intermediario lo traerá desde servidor remoto, entregándolo al cliente que lo solicitó y guardando una copia en el caché. El contenido en el caché es eliminado luego a través de un algoritmo de expiración de acuerdo a la antigüedad, tamaño e historial de respuestas a solicitudes (hits) (ejemplos: LRU, LFUDA y GDSF). Los Servidores Intermediarios para contenido de Red (Web Proxies) también pueden actuar como filtros del contenido servido, aplicando políticas de censura de acuerdo a criterios arbitrarios. Acerca de Squid . Squid es un Servidor Intermediario ( Proxy ) de alto desempeño que se ha venido desarrollando desde hace varios años y es hoy en día un muy popular y ampliamente utilizado entre los sistemas operativos como GNU/ Linux y derivados de Unix®. Es muy confiable, robusto y versátil y se distribuye bajo los términos de la Licencia Pública General GNU (GNU/GPL). Siendo sustento lógico libre, está disponible el código fuente para quien así lo requiera. Entre otras cosas, Squid puede funcionar como Servidor Intermediario ( Proxy ) y caché de contenido de Red para los protocolos HTTP, FTP, GOPHER y WAIS, Proxy de SSL, caché transparente, WWCP, aceleración HTTP, caché de consultas DNS y otras muchas más como filtración de contenido y control de acceso por IP y por usuario. Squid consiste de un programa principal como servidor , un programa para búsqueda en servidores DNS, programas opcionales para reescribir solicitudes y realizar autenticación y algunas herramientas para administración y y herramientas para clientes. Al iniciar Squid da origen a un número configurable (5, de modo predefinido a través del parámetro dns_children) de procesos de búsqueda en servidores DNS, cada uno de los cuales realiza una búsqueda única en servidores DNS, reduciendo la cantidad de tiempo de espera para las búsquedas en servidores DNS. NOTA ESPECIAL: Squid no debe ser utilizado como Servidor Intermediario ( Proxy ) para protocolos como SMTP, POP3, TELNET, SSH, IRC, etc. Si se requiere intermediar para cualquier protocolo distinto a HTTP, HTTPS, FTP, GOPHER y WAIS se requerirá implementar obligatoriamente un enmascaramiento de IP o NAT (Network Address Translation) o bien hacer uso de un servidor SOCKS como Dante (http://www.inet.no/dante/). URL: http://www.squid-cache.org/ Algoritmos de caché utilizados por Squid . A través de un parámetro (cache_replacement_policy) Squid incluye soporte para los siguientes algoritmos para el caché: • LRU Acrónimo de Least Recently Used, que traduce como Menos Recientemente Utilizado. En este algoritmo los objetos que no han sido accedidos en mucho tiempo son eliminados primero, manteniendo siempre en el caché a los objetos más recientemente solicitados. Ésta política es la utilizada por Squid de modo predefinido. • LFUDA Acrónimo de Least Frequently Used with Dynamic Aging, que se traduce como Menos Frecuentemente Utilizado con Envejecimiento Dinámico. En este algoritmo los objetos más solicitados permanecen en el caché sin importar su tamaño optimizando la eficiencia (hit rate) por octetos (Bytes) a expensas de la eficiencia misma, de modo que un objeto grande que se solicite con mayor frecuencia impedirá que se pueda hacer caché de objetos pequeños que se soliciten con menor frecuencia. • GDSF Acrónimo de GreedyDual Size Frequency, que se traduce como Frecuencia de tamaño GreedyDual (codicioso dual), que es el algoritmo sobre el cual se basa GDSF. Optimiza la eficiencia (hit rate) por objeto manteniendo en el caché los objetos pequeños más frecuentemente solicitados de modo que hay mejores posibilidades de lograr respuesta a una solicitud (hit). Tiene una eficiencia por octetos (Bytes) menor que el algoritmo LFUDA debido a que descarta del caché objetos grandes que sean solicitado con frecuencia. Sustento lógico necesario. Para poder llevar al cabo los procedimientos descritos en este manual y documentos relacionados, usted necesitará tener instalado al menos lo siguiente: • Al menos squid -2.5.STABLE6 • httpd-2.0.x (Apache), como auxiliar de caché con aceleración. • Todos los parches de seguridad disponibles para la versión del sistema operativo que esté utilizando. No es conveniente utilizar un sistema con posibles vulnerabilidades como Servidor Intermediario. Debe tomarse en consideración que, de ser posible, se debe utilizar siempre las versiones estables más recientes de todo sustento lógico que vaya a ser instalado para realizar los procedimientos descritos en este manual, a fin de contar con los parches de seguridad necesarios. Ninguna versión de Squid anterior a la 2.5.STABLE6 se considera como apropiada debido a fallas de seguridad de gran importancia. Squid no se instala de manera predeterminada a menos que especifique lo contrario durante la instalación del sistema operativo, sin embargo viene incluido en casi todas las distribuciones actuales. El procedimiento de instalación es exactamente el mismo que con cualquier otro sustento lógico. Instalación a través de yum. Si cuenta con un sistema con CentOS o White Box Enterprise Linux 3 o versiones posteriores, utilice lo siguiente y se instalará todo lo necesario junto con sus dependencias: yum -y install squid httpd Instalación a través de up2date. Si cuenta con un sistema con Red Hat™ Enterprise Linux 3 o versiones posteriores, utilice lo siguiente y se instalará todo lo necesario junto con sus dependencias: up2date -i squid httpd Otros componentes necesarios. El mandato iptables se utilizará para generar las reglas necesarias para el guión de Enmascaramiento de IP. Se instala de modo predefinido en todas las distribuciones actuales que utilicen núcleo (kernel) versiones 2.4 y 2.6. Es importante tener actualizado el núcleo del sistema operativo por diversas cuestiones de seguridad. No es recomendable utilizar versiones del kernel anteriores a la 2.4.21. Actualice el núcleo a la versión más reciente disponible para su distribución. Si cuenta con un sistema con CentOS o White Box Enterprise Linux 3 o versiones posteriores, utilice lo siguiente para actualizar el núcleo del sistema operativo e iptables, si acaso fuera necesario: yum -y update kernel iptables Si cuenta con un sistema con Red Hat™ Enterprise Linux 3 o versiones posteriores, utilice lo siguiente para actualizar el núcleo del sistema operativo, e iptables si acaso fuera necesario: up2date -u kernel iptables Antes de continuar. Tenga en cuenta que este manual ha sido comprobado varias veces y ha funcionado en todos los casos y si algo no funciona solo significa que usted no lo leyó a detalle y no siguió correctamente las indicaciones. Evite dejar espacios vacíos en lugares indebidos. El siguiente es un ejemplo de como si se debe habilitar un parámetro. Bien # Opción correctamente habilitada, sin dejar espacios por delante http_port 3128 Configuración básica. Squid utiliza el fichero de configuración localizado en /etc/ squid /squid.conf, y podrá trabajar sobre este utilizando su editor de texto simple preferido. Existen un gran número de parámetros, de los cuales recomendamos configurar los siguientes: • http_port • cache_dir • Al menos una Lista de Control de Acceso • Al menos una Regla de Control de Acceso • httpd_accel_host • httpd_accel_port • httpd_accel_with_proxy Parámetro http_port: ¿Que puerto utilizar para Squid ? De acuerdo a las asignaciones hechas por IANA y continuadas por la ICANN desde el 21 de marzo de 2001, los Puertos Registrados (rango desde 1024 hasta 49151) recomendados para Servidores Intermediarios (Proxies) pueden ser el 3128 y 8080 a través de TCP. De modo predefinido Squid utilizará el puerto 3128 para atender peticiones, sin embargo se puede especificar que lo haga en cualquier otro puerto disponible o bien que lo haga en varios puertos disponibles a la vez. En el caso de un Servidor Intermediario ( Proxy ) Transparente, regularmente se utilizará el puerto 80 o el 8000 y se valdrá del re-direccionamiento de peticiones de modo tal que no habrá necesidad alguna de modificar la configuración de los clientes HTTP para utilizar el Servidor Intermediario ( Proxy ). Bastará con utilizar como puerta de enlace al servidor . Es importante recordar que los Servidores HTTP, como Apache, también utilizan dicho puerto, por lo que será necesario volver a configurar el servidor HTTP para utilizar otro puerto disponible, o bien desinstalar o desactivar el servidor HTTP. Hoy en día puede no ser del todo práctico el utilizar un Servidor Intermediario ( Proxy ) Transparente, a menos que se trate de un servicio de Café Internet u oficina pequeña, siendo que uno de los principales problemas con los que lidian los administradores es el mal uso y/o abuso del acceso a Internet por parte del personal. Es por esto que puede resultar más conveniente configurar un Servidor Intermediario ( Proxy ) con restricciones por clave de acceso, lo cual no puede hacerse con un Servidor Intermediario ( Proxy ) Transparente, debido a que se requiere un diálogo de nombre de usuario y clave de acceso. Regularmente algunos programas utilizados comúnmente por los usuarios suelen traer de modo predefinido el puerto 8080 (servicio de cacheo WWW) para utilizarse al configurar que Servidor Intermediario ( Proxy ) utilizar. Si queremos aprovechar esto en nuestro favor y ahorrarnos el tener que dar explicaciones innecesarias al usuario, podemos especificar que Squid escuche peticiones en dicho puerto también. Siendo así localice la sección de definición de http_port, y especifique: # # You may specify multiple socket addresses on multiple lines. # # Default: http_port 3128 http_port 3128 http_port 8080 Si desea incrementar la seguridad, puede vincularse el servicio a una IP que solo se pueda acceder desde la red local. Considerando que el servidor utilizado posee una IP 192.168.1.254, puede hacerse lo siguiente: # # You may specify multiple socket addresses on multiple lines. # # Default: http_port 3128 http_port 192.168.1.254:3128 http_port 192.168.1.254:8080 Parámetro cache_mem. El parámetro cache_mem establece la cantidad ideal de memoria para lo siguiente: • Objetos en tránsito. • Objetos frecuentemente utilizados (Hot). • Objetos negativamente almacenados en el caché. Los datos de estos objetos se almacenan en bloques de 4 Kb. El parámetro cache_mem especifica un límite máximo en el tamaño total de bloques acomodados, donde los objetos en tránsito tienen mayor prioridad. Sin embargo los objetos Hot y aquellos negativamente almacenados en el caché podrán utilizar la memoria no utilizada hasta que esta sea requerida. De ser necesario, si un objeto en tránsito es mayor a la cantidad de memoria especificada, Squid excederá lo que sea necesario para satisfacer la petición. De modo predefinido se establecen 8 MB. Puede especificarse una cantidad mayor si así se considera necesario, dependiendo esto de los hábitos de los usuarios o necesidades establecidas por el administrador. Si se posee un servidor con al menos 128 MB de RAM, establezca 16 MB como valor para este parámetro: cache_mem 16 MB Parámetro cache_dir: ¿Cuanto desea almacenar de Internet en el disco duro? Este parámetro se utiliza para establecer que tamaño se desea que tenga el caché en el disco duro para Squid . Para entender esto un poco mejor, responda a esta pregunta: ¿Cuanto desea almacenar de Internet en el disco duro? De modo predefinido Squid utilizará un caché de 100 MB, de modo tal que encontrará la siguiente línea: cache_dir ufs /var/spool/ squid 100 16 256 Se puede incrementar el tamaño del caché hasta donde lo desee el administrador. Mientras más grande sea el caché, más objetos se almacenarán en éste y por lo tanto se utilizará menos el ancho de banda. La siguiente línea establece un caché de 700 MB: cache_dir ufs /var/spool/ squid 700 16 256 Los números 16 y 256 significan que el directorio del caché contendrá 16 directorios subordinados con 256 niveles cada uno. No modifique esto números, no hay necesidad de hacerlo. Es muy importante considerar que si se especifica un determinado tamaño de caché y éste excede al espacio real disponible en el disco duro, Squid se bloqueará inevitablemente. Sea cauteloso con el tamaño de caché especificado. Parámetro ftp_user. Al acceder a un servidor FTP de manera anónima, de modo predefinido Squid enviará como clave de acceso Squid @. Si se desea que el acceso anónimo a los servidores FTP sea más informativo, o bien si se desea acceder a servidores FTP que validan la autenticidad de la dirección de correo especificada como clave de acceso, puede especificarse la dirección de correo electrónico que uno considere pertinente. ftp_user proxy @su-dominio.net Controles de acceso. Es necesario establecer Listas de Control de Acceso que definan una red o bien ciertas máquinas en particular. A cada lista se le asignará una Regla de Control de Acceso que permitirá o denegará el acceso a Squid . Procedamos a entender como definir unas y otras. Listas de control de acceso . Regularmente una lista de control de acceso se establece con la siguiente sintaxis: acl [nombre de la lista] src [lo que compone a la lista] Si se desea establecer una lista de control de acceso que abarque a toda la red local, basta definir la IP correspondiente a la red y la máscara de la sub- red . Por ejemplo, si se tiene una red donde las máquinas tienen direcciones IP 192.168.1.n con máscara de sub- red 255.255.255.0, podemos utilizar lo siguiente: acl miredlocal src 192.168.1.0/255.255.255.0 También puede definirse una Lista de Control de Acceso especificando un fichero localizado en cualquier parte del disco duro, y la cual contiene una lista de direcciones IP. Ejemplo: acl permitidos src "/etc/ squid /permitidos" El fichero /etc/ squid /permitidos contendría algo como siguiente: 192.168.1.1 192.168.1.2 192.168.1.3 192.168.1.15 192.168.1.16 192.168.1.20 192.168.1.40 Lo anterior estaría definiendo que la Lista de Control de Acceso denominada permitidos estaría compuesta por las direcciones IP incluidas en el fichero /etc/ squid /permitidos. Reglas de Control de Acceso . Estas definen si se permite o no el acceso hacia Squid . Se aplican a las Listas de Control de Acceso . Deben colocarse en la sección de reglas de control de acceso definidas por el administrador, es decir, a partir de donde se localiza la siguiente leyenda: # # INSERT YOUR OWN RULE(S) HERE TO ALLOW ACCESS FROM YOUR CLIENTS # La sintaxis básica es la siguiente: http_access [deny o allow] [lista de control de acceso ] En el siguiente ejemplo consideramos una regla que establece acceso permitido a Squid a la Lista de Control de Acceso denominada permitidos: http_access allow permitidos También pueden definirse reglas valiéndose de la expresión !, la cual significa no. Pueden definirse, por ejemplo, dos listas de control de acceso , una denominada lista1 y otra denominada lista2, en la misma regla de control de acceso , en donde se asigna una expresión a una de estas. La siguiente establece que se permite el acceso a Squid a lo que comprenda lista1 excepto aquello que comprenda lista2: http_access allow lista1 !lista2 Este tipo de reglas son útiles cuando se tiene un gran grupo de IP dentro de un rango de red al que se debe permitir acceso, y otro grupo dentro de la misma red al que se debe denegar el acceso. Aplicando Listas y Reglas de control de acceso . Una vez comprendido el funcionamiento de la Listas y las Regla de Control de Acceso , procederemos a determinar cuales utilizar para nuestra configuración. Caso 1. Considerando como ejemplo que se dispone de una red 192.168.1.0/255.255.255.0, si se desea definir toda la red local, utilizaremos la siguiente línea en la sección de Listas de Control de Acceso : acl todalared src 192.168.1.0/255.255.255.0 Habiendo hecho lo anterior, la sección de listas de control de acceso debe quedar más o menos del siguiente modo: Listas de Control de Acceso : definición de una red local completa # # Recommended minimum configuration: acl all src 0.0.0.0/0.0.0.0 acl manager proto cache_object acl localhost src 127.0.0.1/255.255.255.255 acl todalared src 192.168.1.0/255.255.255.0 A continuación procedemos a aplicar la regla de control de acceso : http_access allow todalared Habiendo hecho lo anterior, la zona de reglas de control de acceso debería quedar más o menos de este modo: Reglas de control de acceso : Acceso a una Lista de Control de Acceso . # # INSERT YOUR OWN RULE(S) HERE TO ALLOW ACCESS FROM YOUR CLIENTS # http_access allow localhost http_access allow todalared http_access deny all La regla http_access allow todalared permite el acceso a Squid a la Lista de Control de Acceso denominada todalared, la cual está conformada por 192.168.1.0/255.255.255.0. Esto significa que cualquier máquina desde 192.168.1.1 hasta 192.168.1.254 podrá acceder a Squid . Caso 2. Si solo se desea permitir el acceso a Squid a ciertas direcciones IP de la red local, deberemos crear un fichero que contenga dicha lista. Genere el fichero /etc/ squid /listas/redlocal, dentro del cual se incluirán solo aquellas direcciones IP que desea confirmen la Lista de Control de acceso . Ejemplo: 192.168.1.1 192.168.1.2 192.168.1.3 192.168.1.15 192.168.1.16 192.168.1.20 192.168.1.40 Denominaremos a esta lista de control de acceso como redlocal: acl redlocal src "/etc/ squid /listas/redlocal" Habiendo hecho lo anterior, la sección de listas de control de acceso debe quedar más o menos del siguiente modo: Listas de Control de Acceso : definición de una red local completa # # Recommended minimum configuration: acl all src 0.0.0.0/0.0.0.0 acl manager proto cache_object acl localhost src 127.0.0.1/255.255.255.255 acl redlocal src "/etc/ squid /listas/redlocal" A continuación procedemos a aplicar la regla de control de acceso : http_access allow redlocal Habiendo hecho lo anterior, la zona de reglas de control de acceso debería quedar más o menos de este modo: Reglas de control de acceso : Acceso a una Lista de Control de Acceso . # # INSERT YOUR OWN RULE(S) HERE TO ALLOW ACCESS FROM YOUR CLIENTS # http_access allow localhost http_access allow redlocal http_access deny all La regla http_access allow redlocal permite el acceso a Squid a la Lista de Control de Acceso denominada redlocal, la cual está conformada por las direcciones IP especificadas en el fichero /etc/ squid /listas/redlocal. Esto significa que cualquier máquina no incluida en /etc/ squid /listas/redlocal no tendrá acceso a Squid . Parámetro chache_mgr. De modo predefinido, si algo ocurre con el caché, como por ejemplo que muera el procesos, se enviará un mensaje de aviso a la cuenta webmaster del servidor . Puede especificarse una distinta si acaso se considera conveniente. cache_mgr joseperez@midominio.net Parámetro cache_peer: caches padres y hermanos. El parámetro cache_peer se utiliza para especificar otros Servidores Intermediarios (Proxies) con caché en una jerarquía como padres o como hermanos. Es decir, definir si hay un Servidor Intermediario ( Proxy ) adelante o en paralelo. La sintaxis básica es la siguiente: cache_peer servidor tipo http_port icp_port opciones Ejemplo: Si su caché va a estar trabajando detrás de otro servidor cache, es decir un caché padre, y considerando que el caché padre tiene una IP 192.168.1.1, escuchando peticiones HTTP en el puerto 8080 y peticiones ICP en puerto 3130 (puerto utilizado de modo predefinido por Squid ) ,especificando que no se almacenen en caché los objetos que ya están presentes en el caché del Servidor Intermediario ( Proxy ) padre, utilice la siguiente línea: cache_peer 192.168.1.1 parent 8080 3130 proxy -only Cuando se trabaja en redes muy grandes donde existen varios Servidores Intermediarios ( Proxy ) haciendo caché de contenido de Internet, es una buena idea hacer trabajar todos los caché entre si. Configurar caches vecinos como sibling (hermanos) tiene como beneficio el que se consultarán estos caches localizados en la red local antes de acceder hacia Internet y consumir ancho de banda para acceder hacia un objeto que ya podría estar presente en otro caché vecino. Ejemplo: Si su caché va a estar trabajando en paralelo junto con otros caches, es decir caches hermanos, y considerando los caches tienen IP 10.1.0.1, 10.2.0.1 y 10.3.0.1, todos escuchando peticiones HTTP en el puerto 8080 y peticiones ICP en puerto 3130, especificando que no se almacenen en caché los objetos que ya están presentes en los caches hermanos, utilice las siguientes líneas: cache_peer 10.1.0.1 sibling 8080 3130 proxy -only cache_peer 10.2.0.1 sibling 8080 3130 proxy -only cache_peer 10.3.0.1 sibling 8080 3130 proxy -only Pueden hacerse combinaciones que de manera tal que se podrían tener caches padres y hermanos trabajando en conjunto en una red local. Ejemplo: cache_peer 10.0.0.1 parent 8080 3130 proxy -only cache_peer 10.1.0.1 sibling 8080 3130 proxy -only cache_peer 10.2.0.1 sibling 8080 3130 proxy -only cache_peer 10.3.0.1 sibling 8080 3130 proxy -only Caché con aceleración. Cuando un usuario hace petición hacia un objeto en Internet, este es almacenado en el caché de Squid . Si otro usuario hace petición hacia el mismo objeto, y este no ha sufrido modificación alguna desde que lo accedió el usuario anterior, Squid mostrará el que ya se encuentra en el caché en lugar de volver a descargarlo desde Internet. Esta función permite navegar rápidamente cuando los objetos ya están en el caché de Squid y además optimiza enormemente la utilización del ancho de banda. La configuración de Squid como Servidor Intermediario ( Proxy ) Transparente solo requiere complementarse utilizando una regla de iptables que se encargará de re-direccionar peticiones haciéndolas pasar por el puerto 8080. La regla de iptables necesaria se describe más adelante en este documento. Proxy Acelerado: Opciones para Servidor Intermediario ( Proxy ) en modo convencional. En la sección HTTPD-ACCELERATOR OPTIONS deben habilitarse los siguientes parámetros: httpd_accel_host virtual httpd_accel_port 0 httpd_accel_with_proxy on Proxy Acelerado: Opciones para Servidor Intermediario ( Proxy ) Transparente. Si se trata de un Servidor Intermediario ( Proxy ) transparente, deben utilizarse las siguientes opciones, considerando que se hará uso del caché de un servidor HTTP (Apache) como auxiliar: # Debe especificarse la IP de cualquier servidor HTTP en la # red local o bien el valor virtual httpd_accel_host 192.168.1.254 httpd_accel_port 80 httpd_accel_with_proxy on httpd_accel_uses_host_header on Proxy Acelerado: Opciones para Servidor Intermediario ( Proxy ) Transparente para redes con Internet Exlorer 5.5 y versiones anteriores. Si va a utilizar Internet Explorer 5.5 y versiones anteriores con un Servidor Intermediario ( Proxy ) transparente, es importante recuerde que dichas versiones tiene un pésimo soporte con los Servidores Intermediarios (Proxies) transparentes imposibilitando por completo la capacidad de refrescar contenido. Si se utiliza el parámetro ie_refresh con valor on puede hacer que se verifique en los servidores de origen para nuevo contenido para todas las peticiones IMS-REFRESH provenientes de Internet Explorer 5.5 y versiones anteriores. # Debe especificarse la IP de cualquier servidor HTTP en la # red local httpd_accel_host 192.168.1.254 httpd_accel_port 80 httpd_accel_with_proxy on httpd_accel_uses_host_header on ie_refresh on Lo más conveniente es actualizar hacia Internet Explorer 6.x o definitivamente optar por otras alternativas. Mozilla es en un conjunto de aplicaciones para Internet, o bien Firefox, que es probablemente el mejor navegador que existe en el mercado. Firefox es un navegador muy ligero y que cumple con los estándares, y está disponible para Windows, Linux , Mac OS X y otros sistemas operativos. Estableciendo el idioma de los mensajes mostrados por de Squid hacia el usuario. Squid incluye traducción a distintos idiomas de las distintas páginas de error e informativas que son desplegadas en un momento dado durante su operación. Dichas traducciones se pueden encontrar en /usr/share/ squid /errors/. Para poder hacer uso de las páginas de error traducidas al español, es necesario cambiar un enlace simbólico localizado en /etc/ squid /errors para que apunte hacia /usr/share/ squid /errors/Spanish en lugar de hacerlo hacia /usr/share/ squid /errors/English. Elimine primero el enlace simbólico actual: rm -f /etc/ squid /errors Coloque un nuevo enlace simbólico apuntando hacia el directorio con los ficheros correspondientes a los errores traducidos al español. ln -s /usr/share/ squid /errors/Spanish /etc/ squid /errors Nota: Este enlace simbólico debe verificarse, y regenerarse de ser necesario, cada vez que se actualizado Squid ya sea a través de yum, up2date o manualmente con el mandato rpm. Iniciando, reiniciando y añadiendo el servicio al arranque del sistema. Una vez terminada la configuración, ejecute el siguiente mandato para iniciar por primera vez Squid : service squid start Si necesita reiniciar para probar cambios hechos en la configuración, utilice lo siguiente: service squid restart Si desea que Squid inicie de manera automática la próxima vez que inicie el sistema, utilice lo siguiente: chkconfig squid on Lo anterior habilitará a Squid en todos los niveles de corrida. Depuración de errores Cualquier error al inicio de Squid solo significa que hubo errores de sintaxis, errores de dedo o bien se están citando incorrectamente las rutas hacia los ficheros de las Listas de Control de Acceso . Puede realizar diagnóstico de problemas indicándole a Squid que vuelva a leer configuración, lo cual devolverá los errores que existan en el fichero /etc/ squid /squid.conf. service squid reload Cuando se trata de errores graves que no permiten iniciar el servicio, puede examinarse el contenido del fichero /var/log/ squid /squid.out con el mandato less, more o cualquier otro visor de texto: less /var/log/ squid /squid.out Ajustes para el muro corta-fuegos. Si se tiene poca experiencia con guiones de cortafuegos a través de iptables, sugerimos utilizar Firestarter. éste permite configurar fácilmente tanto el enmascaramiento de IP como el muro corta-fuegos. Si se tiene un poco más de experiencia, recomendamos utilizar Shorewall para el mismo fin puesto que se trata de una herramienta más robusta y completa. • Firestarter: http://www.fs-security.com/ • Shorewall: http://www.shorewall.net/ Re-direccionamiento de peticiones a través de iptables y Firestarter. En un momento dado se requerirá tener salida transparente hacia Internet para ciertos servicios, pero al mismo tiempo se necesitará re-direccionar peticiones hacia servicio HTTP para pasar a través del el puerto donde escucha peticiones Squid (8080), de modo que no haya salida alguna hacia alguna hacia servidores HTTP en el exterior sin que ésta pase antes por Squid . No se puede hacer Servidor Intermediario ( Proxy ) Transparente para los protocolos HTTPS, FTP, GOPHER ni WAIS, por lo que dichos protocolos tendrán que ser filtrados a través del NAT. El re-direccionamiento lo hacemos a través de iptables. Considerando para este ejemplo que la red local se accede a través de una interfaz eth0, el siguiente esquema ejemplifica un re-direccionamiento: /sbin/iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j REDIRECT --to-port 8080 Lo anterior, que requiere un guión de cortafuegos funcional en un sistema con dos interfaces de red , hace que cualquier petición hacia el puerto 80 (servicio HTTP) hecha desde la red local hacia el exterior, se re-direccionará hacia el puerto 8080 del servidor . Utilizando Firestarter, la regla anteriormente descrita se añade en el fichero /etc/firestarter/user-post. Re-direccionamiento de peticiones a través de la opción REDIRECT en Shorewall. La acción REDIRECT en Shorewall permite redirigir peticiones hacia protocolo HTTP para hacerlas pasar a través de Squid . En el siguiente ejemplo las peticiones hechas desde la zona que corresponde a la red local serán redirigidas hacia el puerto 8080 del cortafuegos, en donde está configurado Squid configurado como Servidores Intermediario ( Proxy ) transparente. #ACTION SOURCE DEST PROTO DEST REDIRECT loc 8080 tcp 80
Que es DHCP ? Un servidor Dynamic Host Configuration Protocol (DHCP) asigna dinámicamente las direcciones IP y otras configuraciones de una red determinada a otros ordenadores clientes que estan conectados a la red. Esto simplifica la administración de la red y hace que la conexión de nuevos equipos a la red sea mucho más fácil. Servicio dhcp Todas las direcciones IP de todos los equipos se almacenan en una base de datos que reside en un servidor. Un servidor DHCP puede proporcionar los ajustes de configuración utilizando dos métodos Rango de Direcciónes Este método se basa en la definición de un grupo de las direcciones IP para los clientes DHCP (tambien llamado IP address pool) que suministran sus propiedades de configuración de forma dinámica segun lo soliciten los ordenadores cliente. Cuando un cliente DHCP ya no está en la red durante un período determinado, la configuración vence y la direccion ip del poll es puesta en libertad el uso de otros clientes DHCP. Dirección MAC Este método se basa en utilizar el protocolo DHCP para identificar la dirección de hardware única de cada tarjeta de red conectada a la red y luego es asignada una configuracion constante asi como la misma direccion IP cada vez que la configuración de DHCP del cliente realiza una petición al servidor DHCP desde el mismo dispositivo de red. Instalar un servicio DHCP en Ubuntu y Debian Para instalar el servidor de asignacion automatica de direccion IP ejecutamos el comando: sudo apt-get install dhcp3-server Este sencillo paso instala el servidor en nuestro linux. Configurando el servidor DHCP En el caso que tengan dos interfaces de red (NIC) en su servidor Linux tienen que seleccionar cual van a utilizar para escuchar las peticiones DHCP. Para configurar el servicio, editamos el archivo /etc/default/dhcp3-server, y cambiamos INTERFACES=”eth0″ por la tarjeta de red interna. Es necesario hacer una copia de seguridad del archivo de configuracion: cp /etc/dhcp3/dhcpd.conf /etc/dhcp3/dhcpd.conf.back Configurar utilizando el metodo de rango de direcciones (IP pool) Editamos la configuracion tecleando: sudo vi /etc/dhcp3/dhcpd.conf Y en este archivo cambiamos las siguientes secciones default-lease-time 600; max-lease-time 7200; option subnet-mask 255.255.255.0; option broadcast-address 192.168.1.255; option routers 192.168.1.1; option domain-name-servers 192.168.1.9, 192.168.1.10; option domain-name “guatewireless.org”; subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.10 192.168.1.200; } Guardamos y salimos del archivo. El texto anterior configura el servidor DHCP con los siguientes parametros: * Asignacion a los clientes direcciones IPs del rango de 192.168.1.10 hasta 192.168.1.200 * Prestara la direccion IP por un minimo de 600 segundos, y como maximo permitido de 7200 segundos. * Determina la mascara de subred a 255.255.255.0 * Direccion de broadcast de 192.168.1.255 * Como gateway/pasarela de red/router la direccion 192.168.1.1 * Y los servidores 192.168.1.9 y 10 como sus servidores DNS Configurar utilizando el metodo de direcciones MAC Con este metodo se puede reservar algunas o todas las direcciones IP de nuestra red para determinadas maquinas. Como podran ver la configuracion es muy parecida a la anterior, con la salvedad que para reservar la asignacion de una IP a una determinada NIC (network card interface) debemos de utilizar la etiqueta host default-lease-time 600; max-lease-time 7200; option subnet-mask 255.255.255.0; option broadcast-address 192.168.1.255; option routers 192.168.1.1; option domain-name-servers 192.168.1.9, 192.168.1.10; option domain-name “guatewireless.org”; subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.10 192.168.1.200; } host oracle{ hardware ethernet 00:03:47:31:e1:7f; fixed-address 192.168.1.20; } host printer { hardware ethernet 00:03:47:31:e1:b0; fixed-address 192.168.1.21; } Ahora reiniciamos el servidor dhcp ejecutando el siguiente comando: sudo /etc/init.d/dhcp3-server restart Configurar el cliente DHCP en Linux Ubuntu Si dean configurar un escritorio o maquina con linux como cliente DHCP seguimos los siguientes pasos: * Editamos el archivo de interfaces de red sudo vi /etc/network/interfaces * Debemos de tener las siguientes lineas, tomando en cuenta que eth0 es un ejemplo auto lo eth0 iface eth0 inet dhcp iface lo inet loopback * Salvamos y salimos del archivo * Reiniciamos los servicios de red de Linux Ubuntu sudo /etc/init.d/networking restart Para poder conocer las direcciones asignadas a las maquinas clientes tail -n 15 /var/lib/dhcp3/dhclient.*.leases fuente: http://www.guatewireless.org/os/linux/distros/debian/ubuntu/como-instalar-y-configurar-un-servidor-dhcp-en-linux-ubuntu-debian/
Servidor de archivos gratuito con FREENAS Descarga de la imagen http://freenas.org/doku.php?option=com_versions&Itemid=51 FreeNAS es un sistema operativo basado en FreeBSD que tiene como objetivo su instalación en un pc que servirá como servidor de datos y como servidor para copias de seguridad de los pc’s de vuestra red. Gracias a él y a los programas cliente que utilicemos, podremos evitar perder el tiempo con las copias de seguridad (”backups”) de nuestros datos o archivos, realizándolos de modo automático. A la vez, tendremos a buen recaudo nuestros datos en caso de desastre informático. Nota inicial: este how-to sólo explicará el proceso de instalación básico de FreeNAS. Éste tiene muchísimas opciones de configuración que van más allá de la ’simple’ función de alojar copias de seguridad y que no explicaré aquí. Cada usuario deberá escoger qué funcionalidad de FreeNAS le resulta útil. (*) Hardware: el equipo en el que instalo FreeNAS cuenta con un micro Intel Pentium III, con menos de 256 RAM y con un sólo HD de 30 GB que he particionado para el sistema operativo y para el almacenaje. Con varios HD’s adicionales podrá abastecer a una red mayor de equipos cliente. Lo primero que debemos hacer es decargar FreeNAS. Yo he elegido descargar la .iso (livecd) de la última versión estable desde aquí. Hecho esto, la grabaremos en un cd y lo instalaremos en el pc que hará las funciones de NAS. El proceso de instalación es bien sencillo: Primero, arrancaremos desde el cd (si no os arranca desde él, deberéis habilitar el arranque desde el lector cd o dvd en la bios del pc) para que nos salga el siguiente diálogo: Como deseo utilizar el pc a modo de NAS permanentemente, selecciono la opción “9″ (escribid 9 + Enter). Os aparecerá lo siguiente: Como he dicho antes, quiero instalar FreeNAS en el HD del equipo que va a estar sólo dedicado a la función de NAS. Para este tutorial, y a modo de prueba, he elegido un pc que cuenta sólo con un HD de 30 GB’s. En este caso, deberé elegir la tercera opción que véis en la ventana de arriba: eso instalará el Sistema Operativo FreeNAS en una partición pequeña (mínimo 96 MB) y dejará el resto para almacenaje. Si contáis con un equipo con varios HD’s, podréis dedicar uno de ellos para el sistema y los demás para almacenaje aunque, dado el poco especio que ocupa FreeNAS, con dedicarle una ‘minipartición’ de un HD ya habrá más que suficiente. Una vez he elegido la tercera opción, me preguntará cuánto espacio quiero asignar al sistema. Me informa también de que la cantidad de 96 MB es el mínimo espacio requerido. Una vez ha acabado la instalación, reiniciaremos el sistema (opción núm. 7 + Enter), no sin antes extraer el cd del lector. Una vez haya finalizado el proceso de arranque nos encontraremos con las siguientes opciones: Seleccionaré ahora la primera opción (1 + Enter) para asignar la interface de red que será utilizada. La seleccionaremos y guardaremos antes de salir (”Save and exit”). Acabado esto, iré ahora a por la opción núm. 2 (”Set LAN IP address”). Al entrar en esta opción, encontraremos la pregunta de si queremos asignar la IP interna o si se realizará por DHCP. Dado que el NAS que estoy construyendo se encuentra dentro de una LAN con varios pc’s, asignaré una ip interna al ‘pc-NAS’ dentro de la mencionada LAN. Selecciono “No”. A continuación, deberé asignar una IP dentro del rango de mi red: en mi caso, el rango es 192.68.0.XXX. Elijo entonces en este caso (por ejemplo) 192.68.0.61: Clico en Ok. Elegiré a continuación mi máscara de red y, por último, la puerta de enlace que, en mi caso es 192.68.0.1. Hecho esto, ya hemos acabado con el pc que funcionará como NAS. Me dirijo ahora a otro pc dentro de mi red, abro el navegador para ir a la dirección IP que he asignado previamente (en mi caso, 192.68.0.61). Automáticamente, me aparecerá una ventana de diálogo que nos solicitará nombre de usuario y contraseña. Por defecto, el primero es “admin” y la contraseña “freenas”. Clicaremos en “Ok” y ya veremos por primera vez la webgui de FreeNAS que nos mostrará el estado general del sistema: Lo primero que hago a continuación es dirigirme al Interfaces-Management e Interfaces-LAN para describir y guardar mi configuración de red. Posteriormente, deberé tratar el tema de los discos (Menú Discos – Administración) y el punto de montaje que almacenará nuestros datos. En cuanto a los programas para gestionar las órdenes de backup en los clientes del ‘pc-FreeNAS’, existen muchísimas posibilidades en GNU/Linux con diferentes características: Synkron, FlyBack, Snap Backup, Bacula, TimeVault, etc. Además, siempre existe la posibilidad de programártelo tú mismo. En cuanto a los programas clientes para Windows existen muchas alternativas comerciales y unas cuantas freeware (por ejemplo, uranium). A partir de aquí, cada usuario deberá adaptar la configuración de FreeNAS a sus necesidades y/o gustos. Las opciones que FreeNAS nos ofrece son muy amplias: encriptación de las copias, acceso remoto mediante dns dinámico, diferentes configuraciones de RAID, acceso mediante diferentes protocolos de comunicación, creación de usuarios, accceso inalámbrico, control de temperatura de los HD’s, etc. Ya véis, “un mundo nuevo” que explorar…