como funciona google
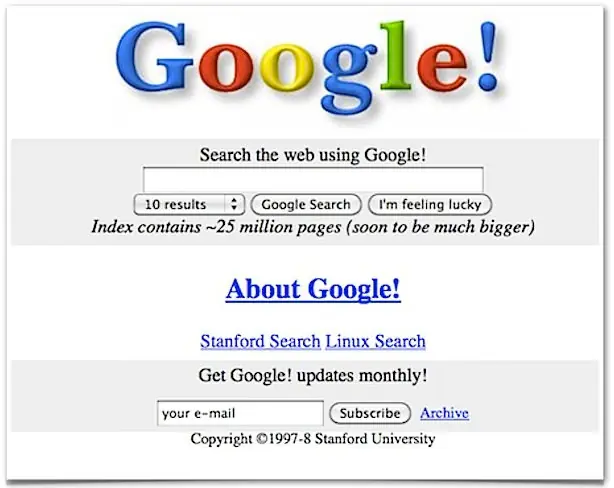
La página de inicio de Google en 1997.
La secuencia de uso es bien conocida:
Necesitamos información de algo en concreto.Entramos en nuestro navegador de internet y accedemos a la página de Google.Escribimos en la caja de texto lo que estamos buscando.Google hace una búsqueda de todas las páginas publicadas en internet.Google muestra en décimas segundos las páginas que considera más relevantes.Hacemos click en el enlace que nos parece más interesante.
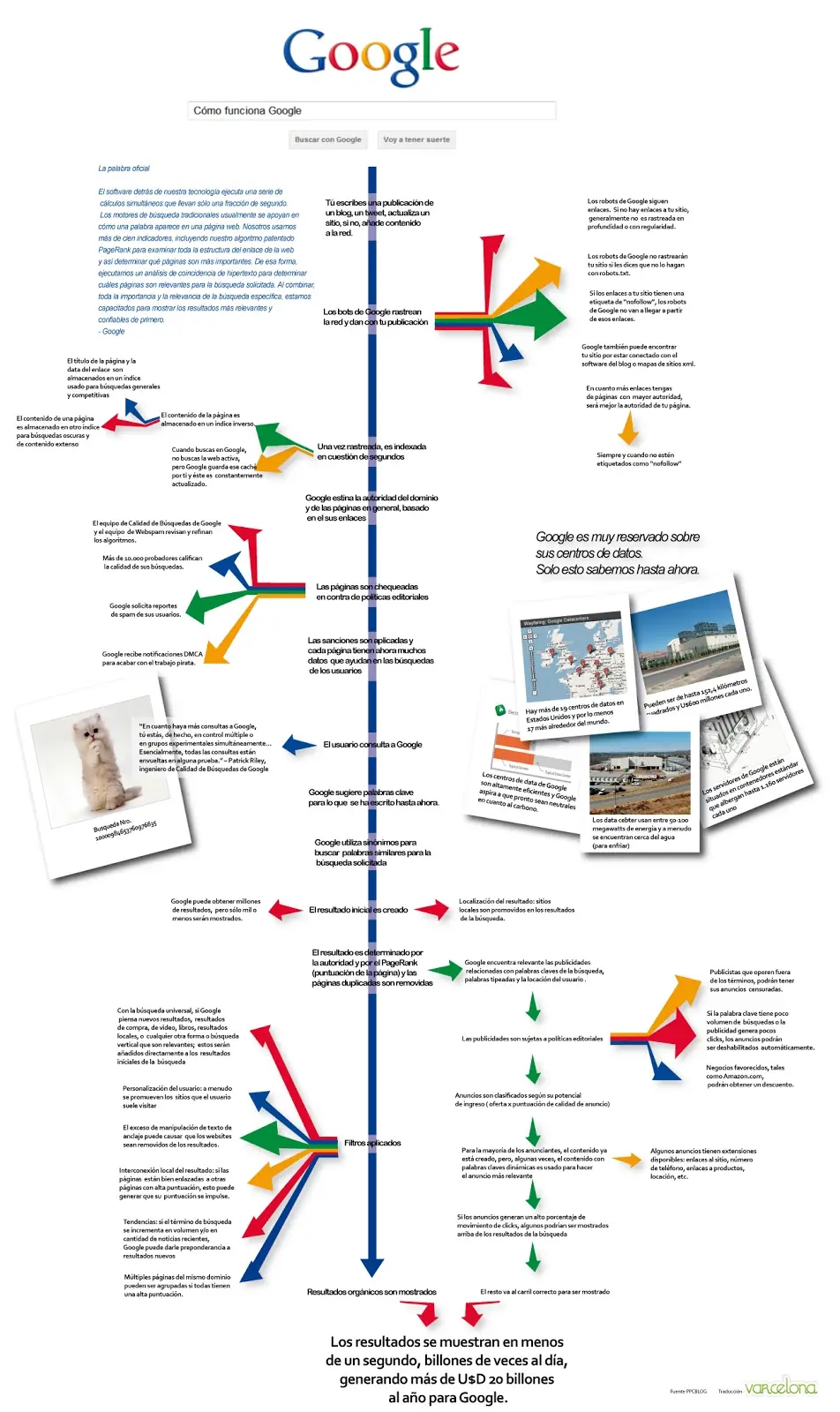
¿Cómo sabe Google acerca de todas las páginas que hay en internet?
Gracias a los primeros protagonistas del proceso: Una especie de programas informáticos creados por Google y que se llaman arañas.
Las arañas se encargan de visitar de manera automática y regular todas las páginas publicadas en internet.
Cuando las visitan, hacen una especie de “fotografía” de esa página para evaluar de qué va esa página y cómo de buena es.
Para saber de qué va la página, las arañas se fijan básicamente en las palabras que aparecen.
Para saber cómo de buena es, las arañas miran, entre otras cosas, si hay otras páginas que tengan un enlace a esa página. Cuantas más páginas la enlacen, se supone que mejor será esa página.
¿Cómo decide Google qué páginas mostrarnos?
Cuando un usuario hace una búsqueda, Google usa la información proporcionada por las arañas para escoger qué páginas va a mostrar en los resultados.
Veamos como funciona esto con un ejemplo.
Imaginemos que estamos buscando “recetas para cena romántica” y que escribimos esto mismo en la página de Google.
Las arañas han inspeccionado las páginas en las que aparecen estas palabras, así que Google será capaz de priorizar una página que contiene “recetas para cena romántica” por encima de otra página que habla de “recetas” en general.
Es decir, Google busca la mayor concordancia posible entre las palabras que usamos al buscar y las palabras que contienen las páginas que nos recomendará.
Pero la concordancia a nivel de palabras no es lo único que Google tiene en cuenta.
Como decíamos antes, Google también trata de recomendar páginas que tengan la mayor calidad posible.

Siguiendo con el ejemplo, si Google detecta que hay una página que contiene las palabras “recetas para cena”, pero esa página está mucho más enlazada que la que contiene “recetas para cena romántica” (mayor concordancia con lo escrito por el usuario), quizás nos ofrezca con mayor prioridad la primera.
Nota: Además del número de páginas que la enlazan, para determinar la calidad de una página, Google evalúa otras muchas cosas (hasta 200 parámetros). A efectos de este artículo, es suficiente con entender que Google usa el sentido común a la hora de determinar la calidad de una página, así que se fija en cosas como: la velocidad a la que carga la página (cuanto más rápido mejor), la frecuencia con la que se actualizan los contenidos de la página (cuanto mayor frecuencia mejor), el número de Likes o Tweets que tiene ese contenido (cuanto mayor sea el número mejor)…
En resumen, Google escucha lo que el usuario busca y trata de ofrecerle las mejores páginas posibles en base a:
- La relevancia del contenido.
- La calidad de la página.

¿qué puedo hacer para que mi pagina sea “de las buenas páginas” a los ojos de Google? A continuación una pequeña pero útil lista de tips:
Actualiza tu contenido constantemente. Hay un dicho en el mundo de la mercadotecnia en linea que dice “Content is king” (El contenido es el rey). Si tu información es valiosa, la gente llegará a tu sitio.
Dale una estructura legible a tu sitio. De nada servirá tener la mejor información del mundo si nadie la puede encontrar. Ayuda a tus visitantes a obtener lo que buscan de la manera mas fácil posible.
Visitas, visitas, visitas. Si Google detecta que tienes muchas visitas en tu sitio, automáticamente te subirá de posición. Uno de los parámetros mas determinantes que utiliza Google para asignar rango es el número de visitas (rango que a su vez, remunera en más visitas). Es algo similar a ver una panadería en la cual hay una larga cola para comprar, el grueso de la gente pensara “el pan debe ser muy bueno ahí”. Entre mas visitas atraigas, mas gente se interesara por tu sitio (y tu negocio).
La verdadera magia de Google reside en su concepción de la web: Google nunca ha entendido la web como un conjunto de documentos de texto, si no como un conjunto de relaciones entre documentos de texto y cada una de éstas relaciones constituye verdaderamente la esencia de Google. En este artículo de HelloGoogle veremos cómo se desarrolla todo el proceso de búsqueda:
Cuando escribimos una búsqueda en www.google.com nuestra petición viaja por el hiperespacio hasta el servidor web de Google. Google recibe más de 1000 peticiones de búsqueda cada segundo de todos los días del año:
•El servidor web de Google está formado por una red de más de 10.000 equipos trabajando en paralelo.

•Cada servidor de la red de Google es extremadamente sencillo y económico: PCs con procesadores X86, disco duro IDE y demás prestaciones estándar.
•El bajo coste del hardware es la base del modelo de negocio de Google y lo que le permite ofrecer la mayoría de sus servicios de manera gratuita.
•Cada servidor falla una vez cada tres años.
•Cada día fallan dos servidores.

•Si se produce cualquier problema de hardware, el software de Google lo hace imperceptible para sus usuarios.
•Google no ha sufrido un fallo general desde el año 2000.
¿Cómo conseguimos que Google muestre nuestra página?

Pues es sencillo de entender, pero no tan fácil de conseguir.
Google simplemente quiere que sus usuarios estén contentos con el funcionamiento del buscador.
Eso significa que se esfuerza en ofrecer las mejores páginas posibles a las búsquedas.
Así que necesitamos tener una página relevante y de calidad.
Si tenemos una página que:
- Tiene contenidos que encajan con lo que buscan los usuarios.
- Tiene tanta calidad que otras páginas nos enlazan a menudo.
- Está tan bien hecha que carga rápido y sin errores.
- Gusta tanto a los que la visitan que a menudo comparten nuestros contenidos en redes sociales.
- Se actualiza muy a menudo.

Descripción general
El motor de indexación de Google esta implementado en C/C++ por razones de eficiencia y puede correr tanto sobre Solaris como sobre Linux. En Google, el proceso de exploración (descargar las páginas a indexar) es realizado por varios exploradores distribuidos. Existe un proceso URLserver que envía listas de URLs a ser descargados a los exploradores. Las páginas que son descargadas son enviadas luego al storeserver. El storeserver comprime y guarda las páginas en un repositorio. Toda página tiene asociado un ID denominado docID que es asignado cada vez que un nuevo URL es interpretado desde una página. La función de indexación es llevada a cabo por un proceso indexador y un clasificador. El indexador lleva a cabo varias funciones: Lee el repositorio, descomprime los documentos y los interpreta, cada documento es convertido en un conjunto de ocurrencias de palabras llamadas hits o aciertos. Cada acierto registra la palabra, posición en el documento y una aproximación del tamaño de la fuente y si está o no en mayúsculas. El indexador distribuye estos aciertos en una serie de “barriles” (barrels) creando un índice. Además, el indexador interpreta todos los enlaces en cada página y guarda información importante sobre los mismos en un archivo llamado anchors, este archivo contiene información suficiente sobre origen y el destino del enlace, y cual es el texto del mismo.
El URLresolver lee registros del archivo de enlaces y convierte URLs relativos en URLs absolutos (por ejemplo si el enlace es desde http://foo.bar/index.htm hacia images/bar.gif el URL absoluto es http://foo.bar/images/bar.gif). Luego convierte los URLs absolutos en docIDs. Pasa el texto del enlace al índice y los asocia con el docID apuntado por el enlace. También genera una base de enlaces que son simplemente pares de docIDs de la forma “desde-hasta”. La base de enlaces es luego usada por el algoritmo de PageRanking para determinar la importancia de cada documento.
El proceso clasificador toma los barrels que están ordenados por docId y los reordena por wordID para generar un índice invertido. Esto es realizado en el mismo lugar para ahorrar espacio auxiliar. El clasificador produce también una lista de wordIDs y desplazamientos al índice invertido. Un programa denominado DumpLexicon toma la lista junto con el léxico producido por el indexador y genera un nuevo léxico para ser usado por el buscador. El buscador es invocado por el servidor web y usa el léxico construido por DumpLexicon junto con el índice invertido y los PageRanks para resolver las búsquedas.
Estructuras de datos
Las estructuras de datos de Google están optimizadas de forma tal que enormes colecciones de documentos puedan ser exploradas, indexadas y buscadas con poco o casi ningún costo.
BigFiles
Un BigFile es un archivo que puede ocupar varios sistemas de ficheros y que se puede direccionar por un desplazamiento de 64 bits, la distribución del archivo en múltiples sistemas de ficheros es manejada automáticamente por la biblioteca de Bigfiles. La biblioteca da al programador una interfaz abstracta que permite manejar los BigFiles como si fueran archivos comunes encargándose de todo el proceso interno necesario para almacenar archivos inmensos.
Repositorio
El repositorio contiene el HTML completo de cada página. Cada página es comprimida usando Zlib. En el repositorio, los documentos se almacenan comprimidos uno a continuación del otro en un archivo secuencial simple y esta prefijados por el docId, longitud y URL como puede verse en la figura 2. El repositorio no requiere otras estructuras para ser usado y accedido. Esto ayuda a darle consistencia al sistema ya que todo el motor de Google y toda la base pueden reconstruirse únicamente a partir del repositorio. Así mismo, el repositorio permite que toda página devuelta por el buscador luego de una consulta pueda ser mostrada al usuario aunque ya no esté disponible en línea. Esto se logra con la opción cached-page del buscador, sumamente útil para sitios antiguos que ya no están, o fueron actualizados, o incluso para los que están fuera de línea en el momento de hacer la consulta.
Document Index
El document index guarda información sobre cada documento. Es un archivo secuencial indexado ISAM ordenado por docID. La información almacenada en cada entrada incluye el estado del documento, una referencia al documento dentro del repositorio, un checksum y varias estadísticas. Si el documento que ha sido explorado contiene también un puntero a un archivo de tamaño variable llamado docinfo que contiene el URL y el título del documento. En el caso contrario, el puntero apunta al URLlist que contiene sólo el URL. Adicionalmente, existe un archivo que es usado para traducir URLs en docIDs, es una lista de URL checksums con sus correspondientes docIds y está ordenada por checksum. Para encontrar el docId de un URL especifico se calcula el checksum del URL y luego se hace una búsqueda binaria dentro de este archivo para encontrar el docID que corresponda al checksum. Los URLs puede ser convertidos en docIDs en lotes haciendo un refundido con este archivo. Esta técnica es usada por el URLresolver para convertir URLs en docIDs. Este modo lotes de actualización es crucial en cuanto a la eficiencia del sistema.
Lexico
El léxico tiene varios formatos diferentes. Un cambio importante es que el léxico puede manejarse en memoria a un precio razonable. El léxico consta de 14 millones de palabras y esta implementado en 2 partes. Una lista de palabras concatenadas entre sí y separadas por NULLs, Y una tabla de hash (dispersión) de punteros. Para varias funciones adicionales, la lista de palabras tiene alguna información auxiliar que esta mas allá del nivel de explicación de este informe.
Hit Lists
Las hit lists (lista de aciertos) es una lista con las ocurrencias de una determinada palabra en un documento en particular incluyendo la posición, fuente y si está o no en mayúsculas. Las hit lists ocupan la mayoría del espacio necesario para los índices, por tal razón deben almacenarse en forma eficiente. Los detalles de codificación de las hit lists se muestran en la siguiente figura:
Este formato de codificación usa dos bytes por cada hit. Hay dos tipos de hits, fancy-hits y plain-hits. Fancy-hits son aquellos que ocurren dentro de una URL, titulo, anchor o meta-tag. Plain-hits son todos los demás. Un plain-hit consiste en un bit que indica si la palabra esta en mayúsculas o minúsculas, tamaño de la fuente y 12 bits para la posición de la palabra en el documento. Todas las posiciones mayores a 4095 se rotulan 4096. El tamaño de la fuente se representa en forma relativa al resto del documento usando 3 bits. Solo 3 valores se usan porque 111 representa un fancy-hit. Un fancy-hit almacena el bit de mayúsculas/minúsculas, el tamaño de la fuente fijada en 111, 4 bits para indicar el tipo de fancy-hit y 8 bits para la posición del mismo. Para enlaces, los 8 bits de posición se separan en 4 bits de posición dentro del texto del anchor y 4 bits para un clave (hash) del docId del documento en el cual esta el enlace.
La longitud de cada hit-list es almacenada antes de la lista misma.
El índice
El índice sin invertir está en realidad parcialmente ordenado. Está distribuido en barrels (se usan 64 barrels). Cada barrel guarda un rango de wordIDs. Si un documento contiene palabras que corresponden a un determinado barrel, los docIds son registrados en el barrel seguidos de una lista de wordIDs con hit-lists que corresponden a dichas palabras. Este esquema requiere un poco mas de espacio al duplicar los docIDs, pero la diferencia es muy chica por un número razonable de buckets y salva mucho tiempo y complejidad de programación en la fase final de indexación.
El índice invertido
El índice invertido consiste en los mismos barrels que el índice pero ya procesado por el clasificador. Para cada wordId válido, el léxico contiene un puntero al barrel correspondiente a la palabra. El puntero apunta a una lista de docIDs junto con sus correspondientes hit-lists. Esta lista representa las ocurrencias de la palabra en todos los documentos indexados.
Procesos
Exploración (crawling)
Ejecutar los web exploradores es un proceso complejo. Hay asuntos altamente intrincados referidos al rendimiento y confiabilidad de los procesos y hasta existen problemas sociales involucrados. El proceso de exploración es sin dudas la más frágil de las aplicaciones ya que implica interactuar con cientos de miles de servidores web y servidores de nombre que están más allá del campo de control del sistema. Para escalar a miles de millones de páginas, Google usa un sistema veloz de exploración distribuido. Un solo URLserver sirve listas de URLs a un número de exploradores (típicamente 3). Tanto el URLserver como los exploradores están implementados en Python. Cada explorador abre unas 300 conexiones HTTP simultáneamente, esto es necesario para poder bajar páginas a un ritmo razonable. En momentos pico el sistema puede descargar 100 páginas por segundo usando 4 exploradores. Esto implica unos 600KBytes por segundo de datos. Un punto mayor de estrés es el DNS lookup, cada explorador mantiene su propio cache de DNS de forma tal de no tener que hacer un DNS lookup antes de explorar cada documento. Cada una de las cientos de conexiones puede estar en un determinado estado: looking up DNS, conectándose al servidor, enviando solicitud o recibiendo respuesta. Estos factores hacen del explorador un componente complejo en el sistema. Se usa IO asincrónica para manejar eventos y un número de colas para mover las URLs solicitados de un estado a otro.
Los exploradores utilizados por Google respetan estrictamente el protocolo “robots.txt” para exclusión de robots en algunos sitios y, además, esperan 1 segundo entre conexión y conexión para un mismo servidor web de forma tal de no alterar significativamente el rendimiento de los mismos.
Indexación
Lo primero necesario para indexar páginas Web es interpretarlas. El proceso de interpretación debe contemplar un gran, enorme, numero de posibles errores que varían desde errores en etiquetas HTML, miles de ceros en medio de un tag, caracteres no-ASCII, etiquetas mal anidadas y no cerradas, etiquetas anidados en forma casi infinita y gran variedad de otros errores. Para maximizar la velocidad Google usa flex para generar un analizador léxico que se alimenta con su propia pila. El desarrollo de este intérprete, que debe correr a una velocidad razonable y ser muy robusto, involucra gran cantidad de trabajo. Una vez interpretado cada documento es codificado en los barrels. Cada palabra es convertida en un Word-Id usando una tabla de hashing mantenida en memoria, o sea, el léxico. Nuevos agregados a la tabla de hashing del léxico son registrados en un archivo. Una vez que las palabras son convertidas en wordIDs sus ocurrencias en el documento son traducidas a hit-lists y son almacenadas en los barrels. La mayor dificultad con la paralelización de la fase de indexado es que el léxico debe compartirse. En lugar de compartir el léxico, Google escribe un registro de todas las palabras extras que no están en el léxico base que se fijó en 14 millones de palabras. De esta forma múltiples indexadores pueden ejecutarse en paralelo y luego el archivo de registro puede ser procesado por el último indexador.
Para generar el índice invertido, el indexador toma cada uno de los barrels ordenándolo por wordID para producir un barrel invertido. El proceso de ordenamiento también es paralelizado para usar tantas máquinas como se pueda simplemente corriendo múltiples ordenadores que pueden procesar diferentes buckets al mismo tiempo. Dado que los barrels no caben en memoria, el clasificador los subdivide en baskets ordenando cada basket en memoria y volcando el contenido combinado al barrel.
Búsqueda (Searching)
El objetivo del proceso de búsqueda es proveer una búsqueda de calidad y eficiente. Muchos de los grandes buscadores comerciales han hecho grandes progresos en cuanto a la eficiencia, por lo que Google se ha concentrado en proveer calidad en los resultados. El proceso de consultas de Google involucra 4 pasos: interpretar la consulta, convertir palabras en wordIDs, buscar el principio de la doclist en el barrel que corresponde a cada palabra. Buscar en los doclists hasta que se encuentre un documento que contiene todos los términos buscados y finalmente computar el orden (ranking) correspondiente de cada documento.
El sistema de ranking
Para ordenar documentos (decidir su importancia respecto de una consulta) Google utiliza un algoritmo propio denominado PageRank. El algoritmo de PageRank está basado en el grafo de enlaces de la web que como tal es un recurso sumamente importante y largamente ignorado en la mayoría de los buscadores. Google dispone de tablas con miles de millones de enlaces de la forma (docID desde-docID hasta), lo cual constituye una buena representación de la web como un grafo de enlaces.
El concepto básico del algoritmo PageRank es que una página es más importante en la medida en que mas páginas apuntan hacia ella. El algoritmo de PageRank extiende este concepto computando no solamente la cantidad de enlaces, sino también normalizando de acuerdo a la cantidad de enlaces en una página, y propagando infinitamente de forma tal que la importancia de una página depende de: cuantas páginas apuntan a ella, de la cantidad de enlaces en estas páginas, y de cuantas y que tan importantes son las páginas que apuntan a las que apuntan a la página. El algoritmo se resume así:
Asumimos que una página "A" tiene páginas T1..Tn que la apuntan. El parámetro d es un parámetro probabilístico que vale entre 0 y 1. Google usa d=0.85. Se define C(A) como la cantidad de enlaces que salen de la página (A). El PageRank de A se calcula como PR(A)=(1-d)+d(PR(T1)/C(T1)+ ... + PR(Tn)/C(Tn))
Notar que los PageRanks forman una distribución probabilística sobre las páginas, la suma de los PageRanks de todas las páginas da 1. El PageRank de una página puede calcularse usando un simple algoritmo iterativo, el PageRank de 26 millones de páginas se puede calcular en pocas horas en una maquina modesta. Dadas n páginas se comienza con PR(Ai)=1/n y luego simplemente se corren x pasadas del algoritmo que calcula el PageRank de cada página hasta que los valores se estabilizan, esta es una técnica comúnmente usada en algoritmia para simplificar algoritmos recursivos.
Justificación intuitiva
El método de PageRank puede verse como un modelo del comportamiento del usuario. Supongamos que tenemos a un navegador aleatorio (random surfer) que dada una página aleatoria elige enlaces y clickea sin usar el botón back, pero eventualmente se aburre y comienza desde otra página aleatoria. ¡La probabilidad de que el visitante llegue a una página es su PageRank!. Y el valor d es la probabilidad de que en una página dada el visitante se aburra y empiece de nuevo desde otra página.
Conclusiones
Google esta diseñado para ser una herramienta de búsqueda escalable eficiente y con un sistema altamente avanzado de ranking de páginas. El uso del algoritmo de PageRank le da una gran calidad a los resultados de búsquedas “comunes”, la enorme cantidad de datos, de lejos la colección mas grande de páginas web del mundo, le permiten resolver eficazmente búsquedas “difíciles” mientras que el repositorio de páginas asegura que los resultados devueltos pueden ser accedidos y consultados por el usuario siendo a su vez de enorme valor como una colección histórica de los documentos en la web.

fuentes: http://www.hellogoogle.com/como-funciona-google-busqueda/
http://www.malditainternet.com/node/60


 y entendia
y entendia 